This post explores some undocumented behavior with TABLESAMPLE, specifically around the REPEATABLE option. TABLESAMPLE is a very useful tool to get a fast page-based sample of large tables. SQL Server uses it behind the scenes to gather sampled statistics.
Syntax
For this post we only need to be concerned with a subset of the syntax:
TABLESAMPLE SYSTEM (sample_number PERCENT ) [ REPEATABLE (repeat_seed) ]
Here’s a quote from that page about how TABLESAMPLE works internally:
TABLESAMPLE SYSTEM returns an approximate percentage of rows and generates a random value for each physical 8-KB page in the table. Based on the random value for a page and the percentage specified in the query, a page is either included in the sample or excluded.
One theory for how TABLESAMPLE works is that SQL Server generates a sequence of random values and does an allocation order scan that skips a page if the random value for that page does not meet the sample percent threshold. If REPEATABLE is used then SQL Server will generate the same sequence of random values each time, but results may be different if the table’s data has changed:
The REPEATABLE option causes a selected sample to be returned again. When REPEATABLE is specified with the same repeat_seed value, SQL Server returns the same subset of rows, as long as no changes have been made to the table. When REPEATABLE is specified with a different repeat_seed value, SQL Server will typically return a different sample of the rows in the table. The following actions to the table are considered changes: inserting, updating, deleting, index rebuilding, index defragmenting, restoring a database, and attaching a database.
How repeatable is REPEATABLE?
One might expect to get the same sample of pages with the REPEATABLE option even if the underlying data has changed but all of the pages remain in the same physical order. It also seems reasonable to think that if we add a page to the end of a table that the sample should stay the same except the new page may or may not be included in the sample. We can do some quick tests:
DROP TABLE IF EXISTS dbo.REPEATABLE_TEST;
CREATE TABLE dbo.REPEATABLE_TEST (
ID BIGINT NOT NULL IDENTITY(1, 1),
FILLER VARCHAR(7000),
PRIMARY KEY (ID)
);
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 3000));
-- returns 3 - 6
-- we skipped the first two pages
-- and included the last four
SELECT ID
FROM dbo.REPEATABLE_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1);
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 3000));
-- returns 3 - 7, same pages as before
SELECT ID
FROM dbo.REPEATABLE_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1);
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
-- returns 3 - 8, includes new page
SELECT ID
FROM dbo.REPEATABLE_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1);
INSERT INTO dbo.REPEATABLE_TEST
VALUES (REPLICATE('Z', 7000));
-- returns 3 - 8, does not include new page
SELECT ID
FROM dbo.REPEATABLE_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1);
So far so good. However, the quote about REPEATABLE also calls out doing an index rebuild. We can see that our table isn’t fragmented at all with this query:
SELECT index_level , page_count , avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats (7, OBJECT_ID(N'dbo.REPEATABLE_TEST') , NULL, NULL , 'DETAILED');
Result set:

With a MAXDOP 1 rebuild I wouldn’t expect the physical order of pages to change at all. Indeed it doesn’t:
We issue the REBUILD:
ALTER TABLE dbo.REPEATABLE_TEST REBUILD WITH (MAXDOP = 1);
However, now we get a completely different sample, despite the table still having no fragmentation. Pages 1, 2, 3, 5, and 8 are included in the results. The table has the same data and physical order as before. Why should the sample change even with the same REPEATABLE value?
Decoding REPEATABLE
Perhaps the REPEATABLE value is somehow combined with some piece of metadata with the table, similar to a salt used for encryption. The OBJECT_ID seems like a reasonable guess except that it won’t change after a rebuild. However, the HOBT_ID of the table does change after a REBUILD. We may be able to get a repeatable sample even after a REBUILD if we’re able to factor in the HOBT_ID somehow.
First let’s put 2537 pages into a new testing table:
DROP TABLE IF EXISTS dbo.REPEATABLE_SALT_TEST;
CREATE TABLE dbo.REPEATABLE_SALT_TEST (
ID BIGINT NOT NULL,
FILLER VARCHAR(7000),
PRIMARY KEY (ID)
);
INSERT INTO dbo.REPEATABLE_SALT_TEST WITH (TABLOCK)
SELECT
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
, REPLICATE('Z', 7000)
FROM master..spt_values;
REPEATABLE allows between 1 and the maximum BIGINT value, 9223372036854775807. However, it’s easy to show through testing that a REPEATABLE value will return the same sample as REPEATABLE value + 4294967296. Perhaps picking a REPEATABLE value of hobt_id % 4294967296 will return the same sample even through a REBUILD.
SELECT hobt_id % 4294967296
FROM sys.partitions
where object_id = OBJECT_ID('REPEATABLE_SALT_TEST');
SELECT COUNT(*), MIN(ID), MAX(ID)
FROM dbo.REPEATABLE_SALT_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1248067584); -- use query value
I get 1306 pages sampled with a minimum value of 3 and a maximum value of 2537. After a REBUILD I get different results:
ALTER TABLE dbo.REPEATABLE_SALT_TEST
REBUILD WITH (MAXDOP = 1);
SELECT hobt_id % 4294967296
FROM sys.partitions
where object_id = OBJECT_ID('REPEATABLE_SALT_TEST');
SELECT COUNT(*), MIN(ID), MAX(ID)
FROM dbo.REPEATABLE_SALT_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (1248133120); -- use query value
Now I get 1272 pages sampled with a minimum value of 6 and a maximum value of 2537. Through trial and error I arrived at one formula which works:
4294967296 - ((hobt_id + @salt) % 4294967296)
Where @salt is a positive integer between 1 and 4294967295. Let’s go back to our current testing table and use a @salt value of 1:
SELECT 4294967296 - ((hobt_id + 1) % 4294967296)
FROM sys.partitions
where object_id = OBJECT_ID('REPEATABLE_SALT_TEST');
SELECT COUNT(*), MIN(ID), MAX(ID)
FROM dbo.REPEATABLE_SALT_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (3046768639);
Now I get 1268 pages sampled with a minimum value of 1 and a maximum value of 2534. After the rebuild I get the same result:
ALTER TABLE dbo.REPEATABLE_SALT_TEST
REBUILD WITH (MAXDOP = 1);
SELECT 4294967296 - ((hobt_id + 2147483648) % 4294967296)
FROM sys.partitions
where object_id = OBJECT_ID('REPEATABLE_SALT_TEST')
SELECT COUNT(*), MIN(ID), MAX(ID)
FROM dbo.REPEATABLE_SALT_TEST
TABLESAMPLE (50 PERCENT)
REPEATABLE (899219456); -- use query value
The formula can also be expressed as:
4294967296 - ((hobt_id + ABS(2147483648 - @salt)) % 4294967296)
With @salt as a positive integer from 0 to 2147483647. This is because there are repeated values in a cycle of 4294967296. More importantly, picking a @seed value of 1 always returns all pages from a table regardless of the sample size.
I admit that there is probably a simpler formula that I missed. Also, none of the above applies to columnstore tables. I doubt that it applies for partitioned rowstore tables as well but I did not test that.
Practical Applications?
There are a few interesting things that can be done with the new knowledge that we have around how REPEATABLE works.
Force an Allocation Order Scan
Normally you can only get an allocation order scan on a table with 64 pages or more unless you use TABLESAMPLE with a sample rate of less than 100%. However, now that we have a seed value that returns all rows no matter what we can force an allocation scan for any size table that returns all rows. Consider a 63 page table written to disk in the wrong order:
DROP TABLE IF EXISTS dbo.FORCE_ALLOCATION_ORDER_SCAN;
CREATE TABLE dbo.FORCE_ALLOCATION_ORDER_SCAN (
ID BIGINT NOT NULL,
PAGE_TURNER VARCHAR(5000) NOT NULL,
PRIMARY KEY (ID)
);
-- add 63 pages with one row per page
-- in reverse clustered index order
DECLARE @i INTEGER = 63;
SET NOCOUNT ON;
WHILE @i > 0
BEGIN
INSERT INTO dbo.FORCE_ALLOCATION_ORDER_SCAN
WITH (TABLOCK)
SELECT @i, REPLICATE('Z', 5000);
SET @i = @i - 1;
END;
This table is very fragmented from the point of view of SQL Server:

Now let’s find the REPEATABLE value which returns all rows:
-- returns 899088385
SELECT 4294967296 - ((hobt_id + ABS(2147483648 - 1)) % 4294967296)
FROM sys.partitions
where object_id = OBJECT_ID('SAMPLE_ALLOCATION_ORDER_TEST');
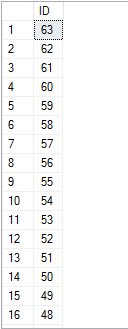
SELECT ID
FROM dbo.FORCE_ALLOCATION_ORDER_SCAN
TABLESAMPLE SYSTEM (99.99999 PERCENT )
REPEATABLE (899088385);
Here is a subset of the results:
Change Cardinality Estimates
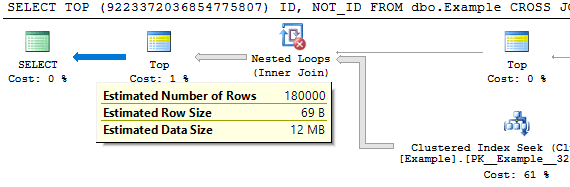
With a repeatable value that returns 100% of the rows in the table we can change the percent to change the cardinality estimate from the table as long as we don’t exceed 99.99999 PERCENT or so.
The below query has a row estimate of 1 row:
SELECT ID FROM dbo.FORCE_ALLOCATION_ORDER_SCAN TABLESAMPLE SYSTEM (0 PERCENT) REPEATABLE (899088385);
Query plan:

And this query has an estimate of 63 rows:
SELECT ID FROM dbo.FORCE_ALLOCATION_ORDER_SCAN TABLESAMPLE SYSTEM (99.99999 PERCENT) REPEATABLE (899088385);
Query plan:
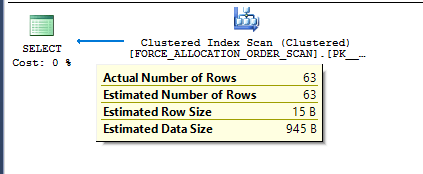
Of course, if the hobt_id for the table ever changes then the results from the query will change. TOP with an OPTIMIZE FOR hint is a good alternative, but TOP PERCENT has the overhead of an added table spool.
Consistent Samples
Suppose I want to create a demo that shows TABLESAMPLE missing all pages with a 50% sample rate against a 20 page table. If I find a REPEATABLE value that works against a table on my machine it likely won’t work for the reader because it will have a different hobt_id. First I need to find a REPEATABLE value that works for my table:
DROP TABLE IF EXISTS dbo.SAMPLE_NO_ROWS;
CREATE TABLE dbo.SAMPLE_NO_ROWS (
PAGE_TURNER VARCHAR(5000) NOT NULL
);
INSERT INTO dbo.SAMPLE_NO_ROWS WITH (TABLOCK)
SELECT TOP 20 REPLICATE('Z', 5000)
FROM master..spt_values t1;
DECLARE @random_seed BIGINT = 0,
@target_num_rows INT = 0,
@found_rows INT,
@stop INT = 0,
@dynamic_sql NVARCHAR(1000);
BEGIN
SET NOCOUNT ON;
WHILE @stop = 0
BEGIN
SET @random_seed = @random_seed + 1;
SET @dynamic_sql = N'SELECT @sampled_row_count = COUNT(*)
FROM dbo.SAMPLE_NO_ROWS
TABLESAMPLE SYSTEM (50 PERCENT)
REPEATABLE(' + CAST(@random_seed AS NVARCHAR(20)) + ')';
EXECUTE sp_executesql @dynamic_sql, N'@sampled_row_count int OUTPUT', @sampled_row_count = @found_rows OUTPUT;
IF @found_rows = @target_num_rows
BEGIN
SET @stop = 1
END;
END;
SELECT @random_seed;
END;
After a lengthy search I got a REPEATABLE value of 823223 on my machine. The following query returns a count of 0 rows:
SELECT COUNT(*) FROM dbo.SAMPLE_NO_ROWS TABLESAMPLE SYSTEM (50 PERCENT) REPEATABLE(823223);
With a hobt_id value of 72057595285143552 we can figure out the @salt value:
SELECT 4294967296 - ((hobt_id + 3046928457) % 4294967296)
FROM sys.partitions
where object_id = OBJECT_ID('SAMPLE_NO_ROWS');
Now I can reproduce the demo from scratch:
DROP TABLE IF EXISTS dbo.SAMPLE_NO_ROWS;
CREATE TABLE dbo.SAMPLE_NO_ROWS (
PAGE_TURNER VARCHAR(5000) NOT NULL
);
INSERT INTO dbo.SAMPLE_NO_ROWS WITH (TABLOCK)
SELECT TOP 20 REPLICATE('Z', 5000)
FROM master..spt_values t1;
SELECT 4294967296 - ((hobt_id + 3046928457) % 4294967296)
FROM sys.partitions
where object_id = OBJECT_ID('SAMPLE_NO_ROWS');
-- count of 0
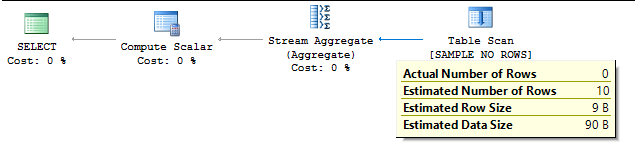
SELECT COUNT(*)
FROM dbo.SAMPLE_NO_ROWS
TABLESAMPLE SYSTEM (50 PERCENT)
REPEATABLE(4294545335); -- use query value
Query plan:
Final Thoughts
Many of the things that I’ll blog about won’t be suitable for production use, but this should be considered especially unsuitable. Microsoft could change the undocumented behavior described here at any time. However, until it is changed it can be useful for demos or for further experimentation. Thanks for reading!