Microsoft has introduced a few improvements to bitmap filters with batch mode. I don’t really define any terms in this post, so if you don’t have a solid grasp of the fundamentals you should consider this blog post by Paul White required reading.
Test Data
Let’s start with a few simple examples that don’t involve columnstore. All of the test queries are simple joins between a dimension and a fact table on a DATETIME column. I’ll use the same dimension table for all of them:
DROP TABLE IF EXISTS dbo.DimDim;
CREATE TABLE dbo.DimDim (
dimDate DATETIME,
PRIMARY KEY (dimDate)
);
INSERT INTO dbo.DimDim VALUES
('20170101'),
('20170102'),
('20170103'),
('20170104'),
('20170105'),
('20170106'),
('20170107'),
('20170108'),
('20170109'),
('20170110'),
('20171201'),
('20171202'),
('20171203'),
('20171204'),
('20171205'),
('20171206'),
('20171207'),
('20171208'),
('20171209'),
('20171210');
Twenty rows in total with 10 dates in January and 10 dates in December. Obviously this isn’t a proper dimension table, but it makes the demos a little simpler. The fact tables have about a million rows in all twelve months of 2017 for a total of about 12 million rows.
Rowstore Heaps
Let’s start with a rowstore heap for the fact table. Code to create and populate the table is below:
DROP TABLE IF EXISTS dbo.FactHeapNoPart;
CREATE TABLE dbo.FactHeapNoPart (
factDate DATETIME,
justTheFacts VARCHAR(100)
);
DECLARE @month INT = 1;
SET NOCOUNT ON;
WHILE @month <= 12
BEGIN
INSERT INTO dbo.FactHeapNoPart
WITH (TABLOCK)
SELECT DATEADD(DAY, t.RN / 38500
, DATEADD(MONTH, @month, '20161201'))
, REPLICATE('FACTS', 20)
FROM
(
SELECT TOP (1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
OPTION (MAXDOP 1);
SET @month = @month + 1;
END;
The first demo query is forced to run in serial:
SELECT * FROM dbo.DimDim dd INNER JOIN dbo.FactHeapNoPart f ON dd.dimDate = f.factDate OPTION (MAXDOP 1);
With a serial query there is no visible bitmap operator as expected:
On my machine, the query requires 190656 logical reads and 2234 ms of CPU time to execute.
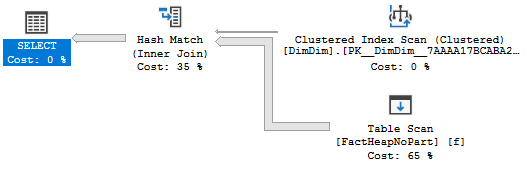
Bumping the query up to MAXDOP 2 results in a bitmap operator:

The bitmap operator isn’t pushed in row due to the data type, but only 769998 rows are sent to the hash match as a result. CPU time required to execute the query falls to 1844 and logical reads stays the same. We did the same amount of IO, which seems perfectly reasonable here.
Rowstore Clustered Indexes
It’s not a very common plan type, but what happens with a hash join on the clustered key of a rowstore table? The code below creates a fact table with the same data as before but now we have a clustered index:
DROP TABLE IF EXISTS dbo.FactClustNoPart;
CREATE TABLE dbo.FactClustNoPart (
factDate DATETIME,
justTheFacts VARCHAR(100)
);
CREATE CLUSTERED INDEX CI ON FactClustNoPart (factDate);
DECLARE @month INT = 1;
SET NOCOUNT ON;
WHILE @month <= 12
BEGIN
INSERT INTO dbo.FactClustNoPart
WITH (TABLOCK)
SELECT DATEADD(DAY, t.RN / 38500
, DATEADD(MONTH, @month, '20161201'))
, REPLICATE('FACTS', 20)
FROM
(
SELECT TOP (1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
OPTION (MAXDOP 1);
SET @month = @month + 1;
END;
All rows are again read from the fact table. The bitmap operator isn’t quite as effective as before. 798498 rows are sent to the join but only 769998 remain after the join.
Could SQL Server do better? Building the hash table is a blocking operator and it should be trivial to keep track of the minimum and maximum join key while building it. In theory, one could imagine a plan with a clustered index seek on the fact table instead of a clustered index scan that takes advantage of the minimum and maximum values found during the hash build phase. This optimization would result in less overall IO. Perhaps this wasn’t implemented because this isn’t a very common plan shape.
Rowstore Partitioned Heaps
Now let’s move onto to a partitioned rowstore heap for the fact table. There is one partition per month and 12 partitions end up with data. Code to create and populate the table is below:
CREATE PARTITION FUNCTION hate_this_syntax_fun
(DATETIME)
AS RANGE RIGHT
FOR VALUES (
'20161231'
, '20170101'
, '20170201'
, '20170301'
, '20170401'
, '20170501'
, '20170601'
, '20170701'
, '20170801'
, '20170901'
, '20171001'
, '20171101'
, '20171201'
, '20180101'
);
CREATE PARTITION SCHEME hate_this_syntax_scheme
AS PARTITION hate_this_syntax_fun
ALL TO ( [PRIMARY] );
DROP TABLE IF EXISTS dbo.FactHeapPart;
CREATE TABLE dbo.FactHeapPart (
factDate DATETIME,
justTheFacts VARCHAR(100)
) ON hate_this_syntax_scheme (factDate);
set statistics io, time on;
DECLARE @month INT = 1;
SET NOCOUNT ON;
WHILE @month <= 12
BEGIN
INSERT INTO dbo.FactHeapPart
WITH (TABLOCK)
SELECT t2.factDate, t2.justTheFacts
FROM
(
SELECT CAST(
DATEADD(DAY, CAST(t.RN / 38500 AS INT)
, DATEADD(MONTH, @month, '20161201')
) AS DATETIME) factDate
, REPLICATE('FACTS', 20) justTheFacts
FROM
(
SELECT TOP (1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
) t2
--WHERE $PARTITION.hate_this_syntax_fun(t2.factDate) = @month + 2
OPTION (MAXDOP 1);
SET @month = @month + 1;
END;
The code above takes a bit longer to execute than I would have liked. There’s a sort before inserting data even with a filter on the partitioning function. I’m not sure why I couldn’t make the sort go away. I expect that it has something to do with data types.
Running the same query as before:
SELECT * FROM dbo.DimDim dd INNER JOIN dbo.FactHeapPart f ON dd.dimDate = f.factDate OPTION (MAXDOP 2);
The plan looks the same as before. The bitmap sends 790371 rows to the hash join. One thing to note is that all partitions are read from the table:

We know that based on the data in the dimension table that SQL Server only needs to read two partitions from the fact table. Could the query optimizer in theory do better than it did? Consider the fact that a partitioned table has at most 15000 partitions. All of the partition values cannot overlap and they don’t change without a DDL operation. When building the hash table the query optimizer could keep track of which partitions have at least one row in them. By the end of the hash build we’ll know exactly which partitions could contain data, so the rest of the partitions could be skipped during the probe phase.
Perhaps this isn’t implemented because it’s important for the hash build to be independent of the probe. Maybe there’s no guarantee available at the right time that the bitmap operator will be pushed all the way down to the scan as opposed to a repartition streams operator. Perhaps this isn’t a common case and the optimization isn’t worth the effort. After all, how often do you join on the partitioning column instead of filtering by it?
It’s worth noting that the theoretical optimization described above still isn’t as good as the collocated join optimization blogged about by Paul White.
Columnstore
Now let’s build a columnstore index with 1048576 rows per rowgroup:
DROP TABLE IF EXISTS dbo.FactCCINoPart;
CREATE TABLE dbo.FactCCINoPart (
factDate DATETIME,
justTheFacts VARCHAR(100),
INDEX CCI CLUSTERED COLUMNSTORE
);
DECLARE @month INT = 1;
SET NOCOUNT ON;
WHILE @month <= 12
BEGIN
INSERT INTO dbo.FactCCINoPart
WITH (TABLOCK)
SELECT t2.factDate, t2.justTheFacts
FROM
(
SELECT CAST(
DATEADD(DAY, CAST(t.RN / 38500 AS INT)
, DATEADD(MONTH, @month, '20161201')
) AS DATETIME) factDate
, REPLICATE('FACTS', 20) justTheFacts
FROM
(
SELECT TOP (1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
) t2
OPTION (MAXDOP 1);
SET @month = @month + 1;
END;
Let’s return to our serial join query:
SELECT * FROM dbo.DimDim dd INNER JOIN dbo.FactCCINoPart f ON dd.dimDate = f.factDate OPTION (MAXDOP 1);
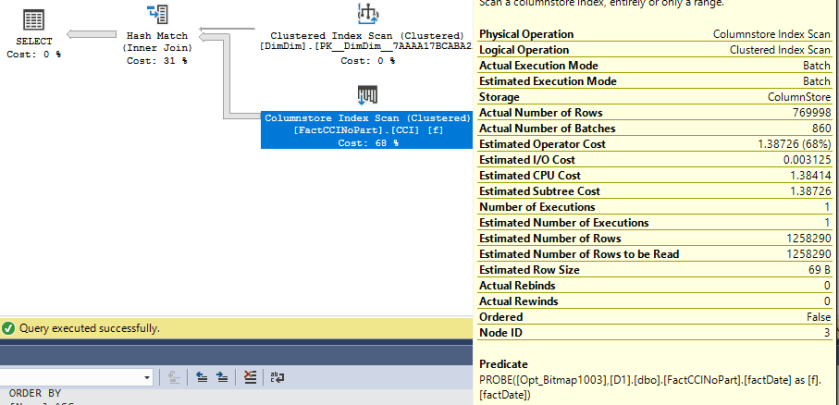
A few interesting things happen. The first is that we get rowgroup elimination even though the dates in the dimension table are spread very far apart:
Table ‘FactCCINoPart’. Segment reads 2, segment skipped 10.
The following simple query doesn’t get rowgroup elimination:
SELECT *
FROM dbo.FactCCINoPart f
WHERE f.factDate IN ('20170101', '20171231')
You can read more about that limitation here. It’s fair to say that the bitmap filter does a better job than expected with rowgroup elimination. According to extended events this is known as an expression filter bitmap. The extended event has a few undocumented properties about the bitmap:

I watched the extended events fly by a few times but it wasn’t clear to me what was going on internally. One possible implementation would be for the hash build to compare each build row to the rowgroup low and high values to figure out which rowgroups could never possibly return matched rows. I strongly suspect that is not the implementation that Microsoft chose. Perhaps they take advantage of the small expected size of the bitmap filter to send information about all of the build rows to do elimination. I don’t know a lot about computer science, but the usual structure of bitmap would not be sufficient because you can’t use such a bitmap to make any determination about inequality comparisons. It can only tell you if an individual row can’t match.
The second interesting thing is that we get an optimized bitmap even for a serial plan:
Optimized Bitmaps
At some point optimized bitmaps were limited to parallel plans. I suspect that restriction was relaxed with the availability of batch mode in a plan but I don’t know for sure. The demos below show optimized bitmaps both improving and degrading performance. The script below creates three tables and takes about three minutes to run on my machine:
DROP TABLE IF EXISTS #t;
SELECT TOP (3000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN into #t
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
-- rowstore dim with an index
-- that includes DimForeignKey
DROP TABLE IF EXISTS dbo.RSJoinIndex;
CREATE TABLE dbo.RSJoinIndex (
IrrelevantKey BIGINT,
SelectKey BIGINT,
DimForeignKey BIGINT,
FilterIndexed INT,
PageFiller VARCHAR(3000),
PRIMARY KEY (IrrelevantKey)
);
INSERT INTO dbo.RSJoinIndex WITH (TABLOCK)
SELECT t.RN, 1, t.RN, 1, REPLICATE('Z', 3000)
FROM #t t
OPTION (MAXDOP 1);
CREATE INDEX IX_RSJoinIndex ON dbo.RSJoinIndex
(FilterIndexed) INCLUDE (DimForeignKey);
CREATE STATISTICS S1 ON dbo.RSJoinIndex (DimForeignKey)
WITH FULLSCAN;
-- rowstore dim with an index
-- that does not include DimForeignKey
DROP TABLE IF EXISTS dbo.RSNoJoinIndex;
CREATE TABLE dbo.RSNoJoinIndex (
IrrelevantKey BIGINT,
SelectKey BIGINT,
DimForeignKey BIGINT,
FilterIndexed INT,
PageFiller VARCHAR(3000),
PRIMARY KEY (IrrelevantKey)
);
INSERT INTO dbo.RSNoJoinIndex WITH (TABLOCK)
SELECT t.RN, 1, t.RN, 1, REPLICATE('Z', 3000)
FROM #t t
OPTION (MAXDOP 1);
CREATE INDEX IX_RSNoJoinIndex ON dbo.RSNoJoinIndex
(FilterIndexed);
CREATE STATISTICS S1 ON dbo.RSNoJoinIndex (DimForeignKey)
WITH FULLSCAN;
-- CCI fact table
DROP TABLE IF EXISTS dbo.CCIFact;
CREATE TABLE dbo.CCIFact (
DimForeignKey BIGINT,
FilterCol BIGINT,
INDEX CCI CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.CCIFact WITH (TABLOCK)
SELECT t.RN , 1 + t.RN % 1000
FROM #t t
OPTION (MAXDOP 1);
CREATE STATISTICS S1 ON dbo.CCIFact (DimForeignKey)
WITH FULLSCAN;
CREATE STATISTICS S2 ON dbo.CCIFact (FilterCol)
WITH FULLSCAN;
All tables have three million rows and the join between them results in 3000 rows. RSJoinIndex is a rowstore table with 3 million rows that contains the join column in a nonclustered index. RSNoJoinIndex is a rowstore table without the join column in a nonclustered index. CCIFact is a columnstore table with three million rows.
Optimized Bitmaps Gone Right
Consider the following query:
SELECT table0.SelectKey FROM dbo.RSNoJoinIndex AS table0 INNER JOIN dbo.CCIFact AS table1 ON table0.DimForeignKey = table1.DimForeignKey WHERE table0.FilterIndexed = 1 AND table1.FilterCol = 1 -- 0.1% of the data OPTION (MAXDOP 1);
The RSNoJoinIndex table has an index with a key column of FilterIndexed and an included column of DimForeignKey. Here’s the plan that I get:

The CCI is used as the build for the hash join. The highlighted filter is an optimized bitmap that’s applied after the index seek but before the key lookup to get the SelectKey column. The bitmap reduces the number of required key lookups from 3000000 to just 3000. The query executes and requires 21874 logical reads from the rowstore table and 437 ms of CPU time on my machine.
Overall this is a reasonable plan and an effective application of a bitmap filter.
Optimized Bitmaps Gone Wrong
Let’s query the table without the join column in the index:
SELECT table0.SelectKey FROM dbo.RSNoJoinIndex AS table0 INNER JOIN dbo.CCIFact AS table1 ON table0.DimForeignKey = table1.DimForeignKey WHERE table0.FilterIndexed = 1 AND table1.FilterCol = 1 -- 0.1% of the data OPTION (MAXDOP 1);
Here’s the plan:

The position of the bitmap has changed so that it’s evaluated after the key lookup. That makes sense because the key lookup returns the column to be filtered against. However, the bitmap filter still reduces the estimated number of key lookups from 3000000 to 3000. This is impossible. The filter can only be applied after the key lookup, so it does not make sense for the bitmap to reduce the number of estimated executions of the key lookup.
Performance is significantly worse with the query now requiring 12199107 logical reads from the rowstore table and 13406 CPU time overall. We can see that the query did three million key lookups:
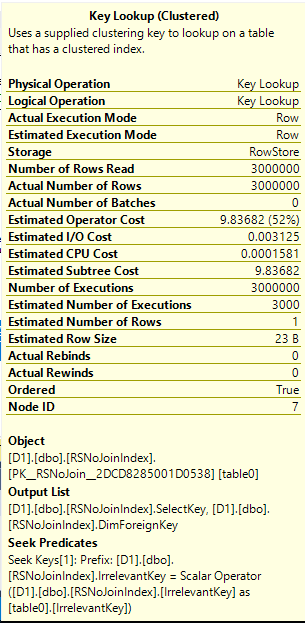
I could only get this type of plan to appear with a columnstore index somewhere present in the query. It can be triggered even with two rowstore tables as long as the query is batch mode eligible. I’ve filed a connect item for this issue. Please vote if you have a moment.
Final Thoughts
Batch mode and columnstore have brought some interesting (and as far as I can tell, undocumented) improvements to bitmap filters. Thanks for reading!