This blog posts investigates the NESTING_TRANSACTION_FULL latch. This latch class can be a bottleneck in extreme ETL workloads. In case you need a quick definition of a latch:
A latch is a lightweight synchronization object that is used by various SQL Server components. A latch is primarily used to synchronize database pages. Each latch is associated with a single allocation unit. A latch wait occurs when a latch request cannot be granted immediately, because the latch is held by another thread in a conflicting mode. Unlike locks, a latch is released immediately after the operation, even in write operations. Latches are grouped into classes based on components and usage. Zero or more latches of a particular class can exist at any point in time in an instance of SQL Server.
Why is the Latch Needed?
Paul Randal has a good explanation here. My experience with it is isolated to parallel SELECT INTO (introduced in SQL Server 2014) and parallel insert into heaps and columnstore (introduced in SQL Server 2016). Each worker thread of the parallel insert has a subtransaction, but only the main transaction can modify the transaction log. Whenever a worker thread needs to modify the transaction log it needs to take an exclusive latch on a subresource under the NESTING_TRANSACTION_FULL latch class. Only one worker thread can hold the latch for the transaction at a time, so this can lead to contention. This is layperson’s explanation based on observed behavior, so please forgive any inaccuracies.
The Test Server
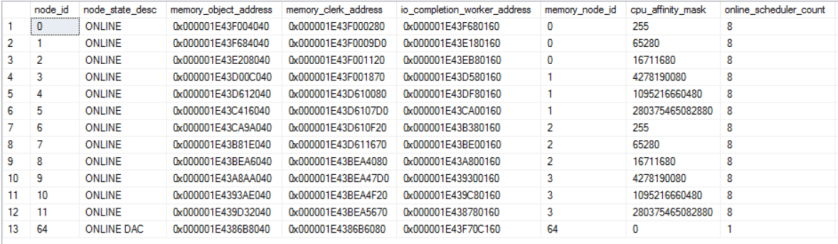
For testing performance and scalability of parallel inserts I prefer to use hardware with a large number of physical cores per socket. I have access to a virtualized test server that’s 4 X 24. I wanted to make tests be as fair as possible, so I decided to only use a single memory node of the server. It seemed logical to pick the node with the least amount of system processes. Here’s a query to view many of them:
SELECT scheduler_id, command
FROM sys.dm_exec_requests r
INNER JOIN sys.dm_exec_sessions s
ON r.session_id = s.session_id
WHERE s.is_user_process = 0
AND scheduler_id IS NOT NULL
ORDER BY scheduler_id;
Here is a partial result set:

I omitted a few processes such as the LOG WRITERS which are on memory node 0. Memory node 1, which covers schedulers 24 to 47, seems like the best choice. All memory nodes have a LAZY WRITER so that can’t be avoided. I’m not doing any full text work that I’m aware of so that just leaves SYSTEM_HEALTH_MONITOR. We have the best, most healthy systems, so I’m sure that process doesn’t do a lot of work.
Resource governor is always enabled on this server, so I can send new sessions to schedulers on memory node 1 with the following commands:
ALTER RESOURCE POOL [default] WITH
(AFFINITY SCHEDULER = (24 to 47));
ALTER RESOURCE GOVERNOR RECONFIGURE;
The Table
For testing I wanted to insert a moderate amount of data while varying MAXDOP. I needed to read enough data for parallel table scans to be effective up to MAXDOP 24 and to write enough data so that parallel insert could be effective. At the same time, I didn’t want to write too much data because that could make running dozens of tests impractical.
I settled on a two column table with an odd partitioning scheme. All of the data is loaded into a single partition so we can run parallel inserts which result in all rows getting sent to a single thread as needed. Most tests spread rows over all parallel worker threads. The FILLER column is there to give the table enough pages to make parallel scans effective. It’s also helpful to run a slower insert query as needed. Other than that, there’s nothing special about the definition or data of the table and it can be changed as desired.
CREATE PARTITION FUNCTION PF_throwaway_1
(BIGINT)
AS RANGE LEFT
FOR VALUES (0, 1, 2, 3);
CREATE PARTITION SCHEME PS_throwaway_1
AS PARTITION PF_throwaway_1
ALL TO ( [PRIMARY] );
DROP TABLE IF EXISTS BASE_TABLE;
CREATE TABLE dbo.BASE_TABLE (
ID BIGINT,
FILLER VARCHAR(1000)
) ON PS_throwaway_1 (ID);
INSERT INTO dbo.BASE_TABLE WITH (TABLOCK)
SELECT 1, REPLICATE('Z', 100)
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
The tempdb database seemed like a good target for writes because I already have 96 data files. There also may be some writing optimizations for tempdb which could be helpful.
A typical test query for observing latch waits looks like something like this:
SELECT ID, REPLICATE('Z', 1000) COL INTO #t
FROM BASE_TABLE
WHERE ID = 1
OPTION (MAXDOP 1);
With MAXDOP varying all the way from 1 to 24.
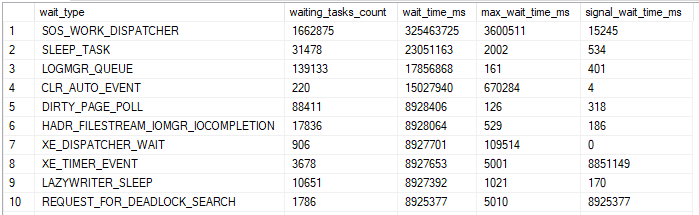
How Many Latches are Taken?
sys.dm_os_latch_stats cannot be used to figure out how many total latches were taken:
sys.dm_os_latch_stats does not track latch requests that were granted immediately, or that failed without waiting.
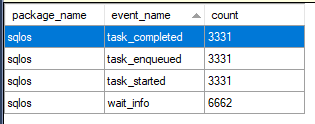
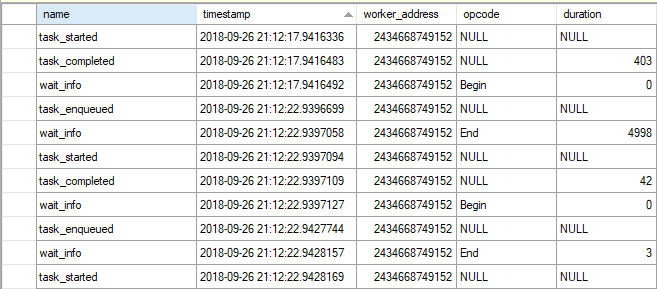
The only way that I know to do that is through extended events. The latch_acquired debug event filtered on the TRAN_NESTING_FULL class is helpful. For data storage targets I used event_counter and histogram. I imagine that these extended events can have a lot of overhead, but I’m doing my testing on a non-production server.
Let’s start with a query that’s not eligible for parallel insert:
DROP TABLE IF EXISTS #t;
SELECT ID, REPLICATE('Z', 1000) COL INTO #t
FROM BASE_TABLE
OPTION (MAXDOP 1);
I expected that no latches will be taken on NESTING_TRANSACTION_FULL. That is indeed what happens.
What about a query that runs at MAXDOP 2 but for which all of the rows are sent to a single worker thread? With four partitions and MAXDOP 2, each worker will be assigned a partition. The worker moves onto the next partition after it reads all of the rows. Skewed data in partitioned tables can lead to parallelism imbalances which can cause problems in real workloads here. It can also be used to our advantage in testing which is what I’m doing here.
DROP TABLE IF EXISTS #t;
SELECT ID, REPLICATE('Z', 1000) COL INTO #t
FROM BASE_TABLE
OPTION (MAXDOP 2);
There is a total of 347435 latch_acquired events for NESTING_TRANSACTION_FULL. The latch was acquired and released 347435 times. If I run a query with rows spread over all parallel workers, such as this one:
DROP TABLE IF EXISTS #t;
SELECT ID, REPLICATE('Z', 1000) COL INTO #t
FROM BASE_TABLE
WHERE ID = 1
OPTION (MAXDOP 2);
I get the same number of latch_acquired events.
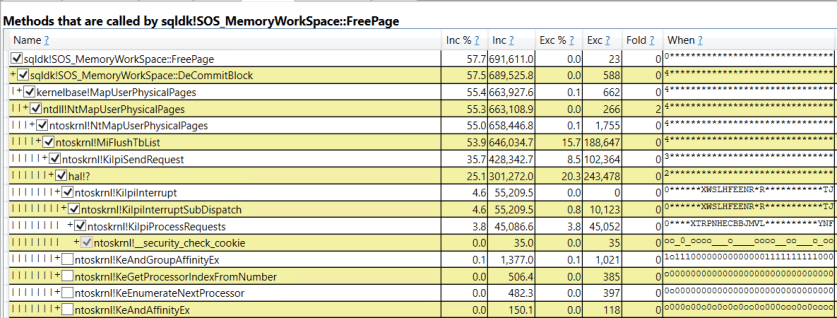
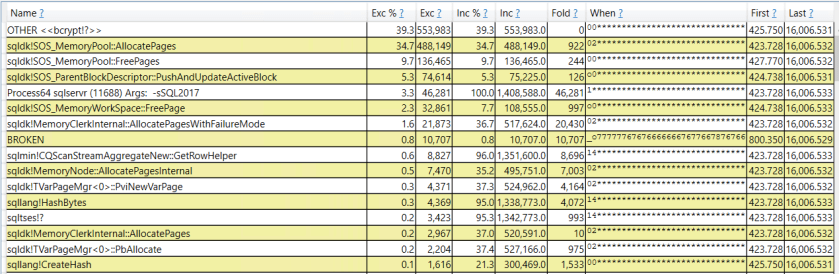
I happened to notice that the query writes 347321 log records to the transaction log. That number is suspiciously close to the number of latches that were acquired. I can get the callstacks around the latch_acquired event by using the technique described here by Jonathan Kehayias. The top three buckets in the histogram each have 115192, 115189, and 115187 events. The callstacks seem to correspond to changing a PFS, GAM, or IAM page. They are reproduced below:
sqlmin.dll!XeSqlPkg::latch_acquired::Publish+0x1a9
sqlmin.dll!LatchBase::RecordAcquire+0x191
sqlmin.dll!LatchBase::AcquireInternal+0x499
sqlmin.dll!ParNestedXdes::GenerateLogRec+0x98
sqlmin.dll!PFSPageRef::ModifyPFSRow+0x68b
sqlmin.dll!ChangeExtStateInPFS+0x2a9
sqlmin.dll!AllocationReq::AllocateExtent+0x33e
sqlmin.dll!AllocationReq::AllocatePages+0x123b
sqlmin.dll!AllocationReq::Allocate+0xf3
sqlmin.dll!ExtentAllocator::PreAllocateExtents+0x457
sqlmin.dll!ExtentAllocatorSingleAlloc::PreAllocate+0x72
sqlmin.dll!ExtentAllocatorSingleAlloc::AllocateExtents+0x26c
sqlmin.dll!CBulkAllocator::AllocateExtent+0x226
sqlmin.dll!CBulkAllocator::AllocatePageId+0xe4
sqlmin.dll!CBulkAllocator::AllocateLinkedAndFormattedLeafPage+0xc1
sqlmin.dll!CHeapBuild::AllocateNextHeapPage+0x1f
sqlmin.dll!CHeapBuild::InsertRow+0x1b1
sqlmin.dll!RowsetBulk::InsertRow+0x23a9
sqlmin.dll!CValRow::SetDataX+0x5b
sqlTsEs.dll!CDefaultCollation::IHashW+0x227
sqlmin.dll!CQScanUpdateNew::GetRow+0x516
sqlmin.dll!CQScanXProducerNew::GetRowHelper+0x386
sqlmin.dll!CQScanXProducerNew::GetRow+0x15
sqlmin.dll!FnProducerOpen+0x5b
sqlmin.dll!XeSqlPkg::latch_acquired::Publish+0x1a9
sqlmin.dll!LatchBase::RecordAcquire+0x191
sqlmin.dll!LatchBase::AcquireInternal+0x499
sqlmin.dll!ParNestedXdes::GenerateLogRec+0x98
sqlmin.dll!PageRef::ModifyBits+0x3e0
sqlmin.dll!ModifyGAMBitAfterNewExtentFound+0xac
sqlmin.dll!AllocExtentFromGAMPage+0x8ef
sqlmin.dll!AllocationReq::AllocateExtent+0x1bb
sqlmin.dll!AllocationReq::AllocatePages+0x123b
sqlmin.dll!AllocationReq::Allocate+0xf3
sqlmin.dll!ExtentAllocator::PreAllocateExtents+0x457
sqlmin.dll!ExtentAllocatorSingleAlloc::PreAllocate+0x72
sqlmin.dll!ExtentAllocatorSingleAlloc::AllocateExtents+0x26c
sqlmin.dll!CBulkAllocator::AllocateExtent+0x226
sqlmin.dll!CBulkAllocator::AllocatePageId+0xe4
sqlmin.dll!CBulkAllocator::AllocateLinkedAndFormattedLeafPage+0xc1
sqlmin.dll!CHeapBuild::AllocateNextHeapPage+0x1f
sqlmin.dll!CHeapBuild::InsertRow+0x1b1
sqlmin.dll!RowsetBulk::InsertRow+0x23a9
sqlmin.dll!CValRow::SetDataX+0x5b
sqlTsEs.dll!CDefaultCollation::IHashW+0x227
sqlmin.dll!CQScanUpdateNew::GetRow+0x516
sqlmin.dll!CQScanXProducerNew::GetRowHelper+0x386
sqlmin.dll!CQScanXProducerNew::GetRow+0x15
sqlmin.dll!XeSqlPkg::latch_acquired::Publish+0x1a9
sqlmin.dll!LatchBase::RecordAcquire+0x191
sqlmin.dll!LatchBase::AcquireInternal+0x499
sqlmin.dll!ParNestedXdes::GenerateLogRec+0x98
sqlmin.dll!PageRef::ModifyBits+0x3e0
sqlmin.dll!ChangeExtStateInIAM+0x2ac
sqlmin.dll!AllocationReq::AllocatePages+0x17e5
sqlmin.dll!AllocationReq::Allocate+0xf3
sqlmin.dll!ExtentAllocator::PreAllocateExtents+0x457
sqlmin.dll!ExtentAllocatorSingleAlloc::PreAllocate+0x72
sqlmin.dll!ExtentAllocatorSingleAlloc::AllocateExtents+0x26c
sqlmin.dll!CBulkAllocator::AllocateExtent+0x226
sqlmin.dll!CBulkAllocator::AllocatePageId+0xe4
sqlmin.dll!CBulkAllocator::AllocateLinkedAndFormattedLeafPage+0xc1
sqlmin.dll!CHeapBuild::AllocateNextHeapPage+0x1f
sqlmin.dll!CHeapBuild::InsertRow+0x1b1
sqlmin.dll!RowsetBulk::InsertRow+0x23a9
sqlmin.dll!CValRow::SetDataX+0x5b
sqlTsEs.dll!CDefaultCollation::IHashW+0x227
sqlmin.dll!CQScanUpdateNew::GetRow+0x516
sqlmin.dll!CQScanXProducerNew::GetRowHelper+0x386
sqlmin.dll!CQScanXProducerNew::GetRow+0x15
sqlmin.dll!FnProducerOpen+0x5b
sqlmin.dll!FnProducerThread+0x80b
The callstack with the next most events only has 472, so I consider those three to be the important ones.
The data for the temp table takes up 7373280 KB of space. That’s about 115208 extents, and multiplying that again by 3 is again suspiciously close to the previous two numbers. It seems reasonable to conclude that the number of NESTING_TRANSACTION_FULL latches required for a minimally logged parallel insert into a heap will be approximately equal to 3 times the number of extents needed for the new data. Note that this is an approximation, and there are slight changes to the latch acquire count as MAXDOP changes.
Slowing Down the Insert
I changed the insert query to the following:
DROP TABLE IF EXISTS #t;
SELECT ID
, CASE WHEN CHARINDEX('NO U', FILLER) = 0
THEN REPLICATE('Z', 1000)
ELSE NULL END COL INTO #t
FROM BASE_TABLE
WHERE ID = 1
OPTION (MAXDOP 1);
The point is to require more CPU to insert the same volume of data as before. Here is a table showing elapsed time along with wait information for the latch:
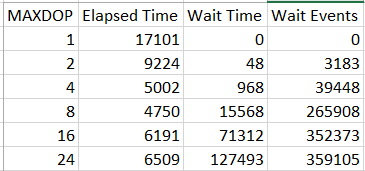
I didn’t include CPU time because SET STATISTICS TIME ON was wildly inaccurate for queries with higher DOP. Elapsed time decreases from MAXDOP 1 to MAXDOP 8 but starts to increase after MAXDOP 8. The total wait time dramatically increases as well. In addition, nearly all latch acquires at MAXDOP 16 or MAXDOP 24 had to be waited on.
We know that only one worker can get the exclusive latch for the transaction at a time. Let’s use a greatly simplified model for what each parallel worker does for this query. It reads a row, does processing for a row, and goes on to the next one. Once it has enough rows to write out a log record it tries to acquire the latch. If no one else has the latch in exclusive mode it can get the latch, update some structure in the parent transaction, release the latch, and continue reading rows. If another worker has the latch in exclusive mode then it adds itself to the FIFO wait queue for the latch subresource and suspends itself. When the resource is available the worker status changes from SUSPENDED to RUNNABLE. When it changes again from RUNNABLE to RUNNING it acquires the latch, updates some structure in the parent transaction, releases the latch, and continues working until it either needs to suspend again or hits the end of its 4 ms quantum. When it hits the end of its 4 ms quantum it will immediately select itself to run again because there are no other runnable workers on the scheduler.
So what determines the level of contention? One important factor is the number of workers that are contending over the same subresource. For this latch and type of query (rows are pretty evenly distributed between worker threads), this is simply MAXDOP. There’s a tipping point for this query where adding more workers is simply counterproductive.
For years I’ve seen people in the community state that running queries at MAXDOP that’s too high can be harmful. I’ve always been after simple demos that show why that can happen. The NESTING_TRANSACTION_FULL latch is an excellent example of why some queries run longer if MAXDOP is increased too far. There’s simply too much contention over a shared resource.
Speeding up the Insert
Let’s go back to the original query which is able to insert data at a faster rate:
DROP TABLE IF EXISTS #t;
SELECT ID, REPLICATE('Z', 1000) COL INTO #t
FROM BASE_TABLE
WHERE ID = 1
OPTION (MAXDOP 2);
Here is a table showing elapsed time along with wait information for the latch:

We see a similar pattern to the previous query. However, run times are fairly close at MAXDOP 16 and 24. How can that be? Based on the MAXDOP 1 run times we know that this query only has to do about 50% of the CPU work compared to the other query.
Consider the rate of latch acquisition. Let’s suppose that we need to take around 360000 latches for both queries and suppose that their parallel workers never need to wait on anything. Based on the MAXDOP 1 runtime for this query we can work at a rate of 360000/(9565/4) = 150 latches per 4 ms quantum per worker. For the slower query, we can only work at a rate of 360000/(17101/4) = 84 latch acquires per 4 ms quantum. Of course, the assumption that none of the workers for these parallel queries will wait is wrong. We can see high wait times at high MAXDOP. The key is to think about what each worker does between waits. It’s true that the first query needs to do more CPU work overall. However, at MAXDOP 24 we can have up to 23 workers in the wait queue for the latch. It seems unlikely that a worker will be able to acquire many latches in a row without waiting. At high MAXDOP workers will often need to suspend themselves. As long as the amount of work between log records is significantly less than the 4 ms quantum then there won’t be a run time difference between the queries. The query with CHARINDEX will do useful CPU work while the query without it will wait. That’s why the query without CHARINDEX has more aggregate wait time at MAXDOP 24. The workers are able to enter a SUSPENDED state faster than the workers for the other queries, but that isn’t going to make the query complete any faster.
Adding a Busy Scheduler
In the previous tests we only had a single user query running on the 24 schedulers available to us. That isn’t a realistic real world scenario. There will often be other queries competing for CPU resources on the same schedulers. Now I’ll add a single MAXDOP 1 query which won’t finish its work for many hours. It’s designed to burn CPU as efficiently as possible in that there are very few possible waits. The worker thread should be able to use its full 4 ms quantum almost always. Here’s the query that I used:
SELECT TOP (1) t1.high + t2.high + t3.high + t4.high
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
CROSS JOIN master..spt_values t4
ORDER BY t1.high + t2.high + t3.high + t4.high
OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL)
I believe the query was assigned to scheduler 27. It stayed there until I cancelled the query.
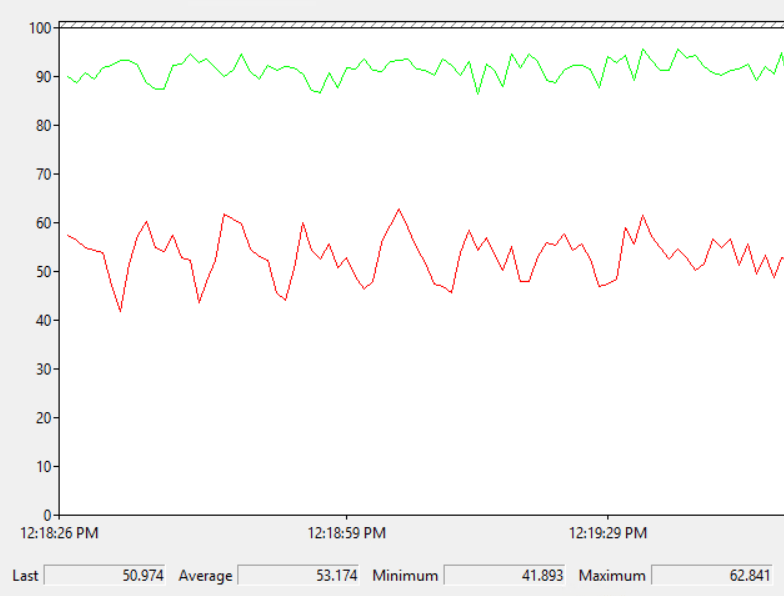
What happens to the performance of the parallel SELECT INTO when one of the schedulers for its workers shares a scheduler with the MAXDOP 1 query? To make that happen I kept track of where the parallel enumerator was and made sure that 8 of the parallel workers were always assigned to the soft-NUMA node which contained the scheduler of the MAXDOP 1 query. I don’t love my readers enough to configure soft NUMA so I only have test results for MAXDOP 8, 16, and 24 (auto soft-NUMA splits a virtualized 24 scheduler memory node into 3 groups of 8 schedulers). Here are the test results:

Query run times have dramatically increased. Why did that happen? Recall that latches can be requested at a high rate for the workers of our parallel workers. If a worker requests a latch that it can’t get it suspends itself. However, what happens if there’s another worker on that same scheduler that can use its full 4 ms quantum, such as our MAXDOP 1 query. Even if the latch resource is available after 1 ms, the worker for the parallel worker won’t be able to run for a minimum of 4 ms. It needs to wait for the MAXDOP 1 worker to yield the scheduler. The FIFO nature of the latch queue is harmful here from a query runtime point of view. A scheduling delay between RUNNABLE and RUNNING for a single worker can cause all other parallel worker threads to wait.
It is interesting that run time gets better with higher MAXDOP. This is the opposite pattern of before. Let’s look at the number of latch acquires bucketed by scheduler_id for the MAXDOP 8 query:

The worker sharing a scheduler with the MAXDOP 1 query does get about 10% fewer latches. However, the FIFO nature of the queue means that work cannot balance well between schedulers, even though the parallel scan and insert operators distribute rows on a demand basis. Based on the wait event counts, it’s fair to guess that the worker had to wait on the latch about 33/36 = 91.6% of the time. If the worker on scheduler 27 suspends itself it’ll need to wait 4 ms before it can start running again. That gives us a minimum run time for the query of 39961*4*(33/36) = 146523, which is fairly close to the true elapsed time of 141162.
Now consider the latch acquire distribution for the MAXDOP 16 query:

The latches are spread fairly evenly over worker threads. Scheduler 27 only had 20968 latch acquires, so we can calculate our guess for a run time floor as 20968*4*(35/36) = 81542 ms. This is close to the true elapsed time of 82245 ms.
The most important takeaway from this section is that query runtime for parallel inserts or parallel SELECT INTO can dramatically increase if there’s any other work happening on those schedulers. Increasing MAXDOP can apparently be helpful in working around scheduler contention, but it will make latch contention worse. I’ve never seen a practical example where that strategy works out.
Adding More CPU Work
Keeping the busy scheduler, let’s go back to the query with CHARINDEX:
DROP TABLE IF EXISTS #t;
SELECT ID
, CASE WHEN CHARINDEX('NO U', FILLER) = 0
THEN REPLICATE('Z', 1000)
ELSE NULL END COL INTO #t
FROM BASE_TABLE
WHERE ID = 1
OPTION (MAXDOP 1);
Here are the test results at MAXDOP 8, 16, and 24:
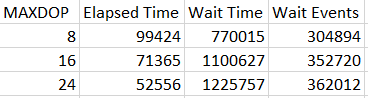
I was surprised to see faster query execution times for the query that effectively needs to do more work. I ran the tests a few times and always saw the same pattern. It certainly makes sense that this query will spend less time on latch waits than the other one, but the exact mechanisms behind faster run times aren’t clear to me yet. Here’s the count of latches split by worker for the CHARINDEX query:
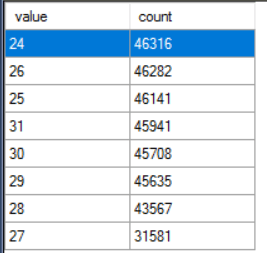
Here’s the count for a different test run of the query without CHARINDEX:

The CHARINDEX query has fewer latch acquires on scheduler 27. That allows the other schedulers to get more latches and to do more work. That explains the difference in run time, but I don’t understand why it happens. Perhaps the worker for the CHARINDEX query on scheduler 27 is able to exhaust its 4 ms quantum more often than the other query which allows the other workers to cycle through the latch while the MAXDOP 1 query is on scheduler 27. I may investigate this more another time.
Real World Problems
Adding a single MAXDOP 1 query to the workload in some cases made the parallel query take almost 30 times as long. Is this possible in the real world?
Some parallel inserts generate data to be inserted at a fast rate. Consider the results of a parallel batch mode hash join, for example. Multiple exclusive latches on NESTING_TRANSACTION_FULL seem to be required for every transaction log record that is generated. This can slow down queries and limit overall scalability. The FIFO nature of the queue is especially problematic when there are high signal waits (delays from changing worker status from RUNNABLE to RUNNING). A worker from another query on a scheduler can lead to waits for every parallel worker for an insert or SELECT INTO. There are many reasons for high signal waits: spinlock pressure, some external waits, nonyielding schedulers, and workers that choose not to yield for reasons only known to them. Query performance can degrade even with just a simple query that exhausts its 4 ms quantum every time, as was shown in this blog post.
Lowering MAXDOP can help, but it may not be enough for some workloads. The high rate of exclusive NESTING_TRANSACTION_FULL latch requests feels like a scalability problem that only Microsoft can solve. It would be great if each subtraction was able to update the log and the subtractions could be grouped as needed, such as for query rollback. I can’t speak to the complexities in making such a code change.
Final Thoughts
The NESTING_TRANSACTION_FULL latch can be a scalability and performance bottleneck on systems that do many concurrent parallel insert queries or parallel SELECT INTO queries. If you see this bottleneck for your workload, there are a few things that might be helpful to keep in mind:
- The number of latches taken is proportional to the number of log records needed for the transaction. With minimal logging, the number of exclusive latches taken is about equal to 3 * number of extents.
- Latch contention gets worse as
MAXDOP increases.
- Latch contention gets worse as the rate of latch requests increases. In other words, queries that can generate their data to be inserted very efficiently are more impacted.
- Delays keeping parallel workers from moving to
RUNNING from the RUNNABLE queue for even one parallel worker can have a disastrous effect on query performance. There are many possible scenarios in which this can happen.
Thanks for reading!