A KB article was recently published that suggested that memory time-out behavior was changed for CCI inserts:
When you try to create a Columnstore Index on a table in Microsoft SQL Server 2016 or 2017, the request may fail after 25 seconds with memory time-out error 8645, depending on how many memory consuming queries are running concurrently and/or how much memory is available at the time of the request. The memory time-out error may occur even when you configure longer memory request time-out at an instance level or at a resource pool level.
I’ve never seen that error occur for serial inserts. Serial inserts time out after 25 seconds and execute with minimum required memory. They write directly to the delta store instead of attempting compression. So it looked like this change affects parallel inserts but the details weren’t at all clear to me.
Time out for time-outs
Why should we care about memory grant timeouts for CCI insert queries? Simply put, lots of bad things can happen when those queries can time out, both for serial and for parallel inserts. For serial insert queries, I’ve observed deadlocks, extremely poor performance along with long SLEEP_TASK waits, and extremely long rollbacks. For parallel insert queries, I’ve observed queries that run seemingly forever, poor performance of the SELECT part, and error 8645. You probably don’t want any of that occurring in production. It would be very helpful if it was possible to extend the 25 second time-out for queries that insert into columnstore tables.
Time out for time-outs
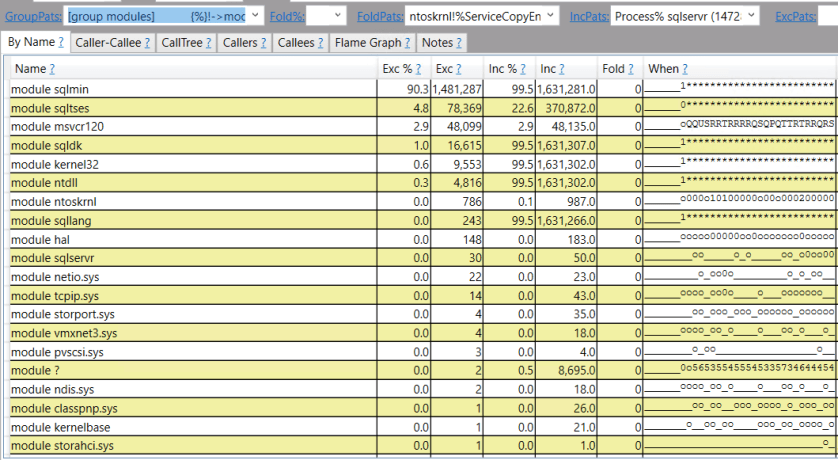
I’ve found it extremely useful to keep around a 2017 RTM environment with no CUs to figure when issues related to columnstore were introduced into the product. First we’ll take a look at the behavior on 2017 RTM to see error 8645 in action. I want a relatively simple parallel insert query that will run for longer than 25 seconds and will take a large memory grant. I decided on the following query:
INSERT INTO dbo.TARGET_CCI_1 WITH (TABLOCK) SELECT ca.SLOW, ca.INFLATE_GRANT FROM (VALUES (0), (1), (2), (3)) v(x) CROSS APPLY ( SELECT TOP (1048576) sc.SLOW, sc.INFLATE_GRANT FROM dbo.SLOW_TO_COMPRESS sc WHERE sc.FOR_SEEKING = v.x ) ca OPTION (MAXDOP 2);
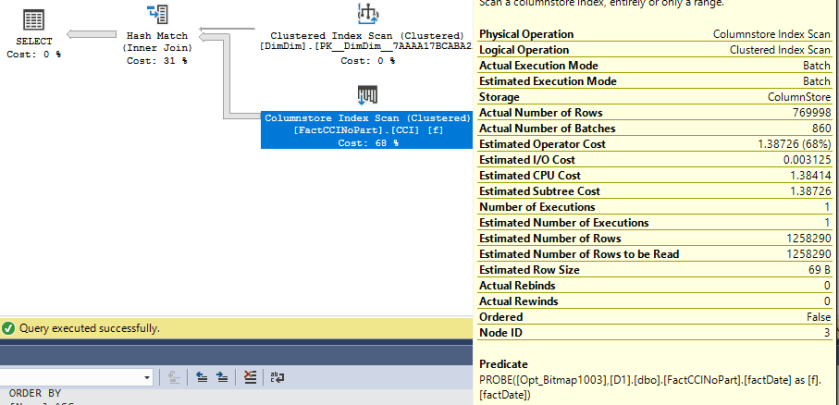
I get the properties that I’m after with a few undocumented tricks. The inflate grant column is a VARCHAR(8000) column. That data type significantly increases the memory grant for parallel inserts even with all NULLs. For the SLOW column, I’m loading integers evenly distributed between 0 and 7999. That data pattern can take longer than expected to compress. The worst case is with around 16000 distinct evenly distributed integers. If you’d like to understand why check out this answer by Paul White. Finally, the CROSS APPLY pattern means that I’ll get demand-based parallelism with each nested loop execution reading exactly enough rows from SLOW_TO_COMPRESS to fill up one rowgroup. It may be helpful to look at the query plan:
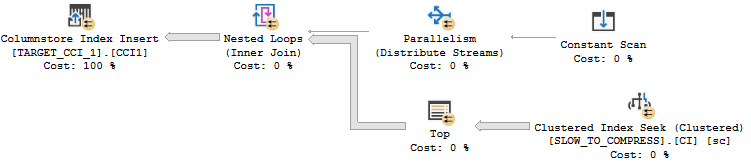
The query takes about 40 seconds to execute on my machine. If you’d like to follow along at home, set max server memory to 8000 MB and run the following code:
DROP TABLE IF EXISTS dbo.SLOW_TO_COMPRESS; CREATE TABLE dbo.SLOW_TO_COMPRESS ( FOR_SEEKING INT NULL, SLOW BIGINT NULL, INFLATE_GRANT VARCHAR(8000) NULL ); CREATE CLUSTERED INDEX CI ON dbo.SLOW_TO_COMPRESS (FOR_SEEKING); INSERT INTO dbo.SLOW_TO_COMPRESS WITH (TABLOCK) SELECT q.RN / 1048576, RN % 10000, NULL FROM ( SELECT TOP (4 * 1048576) -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) q OPTION (MAXDOP 1); GO DECLARE @table_id INT = 1, @sql NVARCHAR(4000); WHILE @table_id <= 6 BEGIN SET @sql = N'DROP TABLE IF EXISTS dbo.TARGET_CCI_' + CAST(@table_id AS NVARCHAR(2)) + N'; CREATE TABLE dbo.TARGET_CCI_' + CAST(@table_id AS NVARCHAR(2)) + N'( SLOW BIGINT NULL, INFLATE_GRANT VARCHAR(8000) NULL, INDEX CCI1 CLUSTERED COLUMNSTORE )'; EXEC sp_executesql @sql; SET @table_id = @table_id + 1; END; GO CREATE OR ALTER PROCEDURE dbo.INSERT_INTO_TARGET_CCI (@table_id INT) AS BEGIN DECLARE @sql NVARCHAR(4000) = N'INSERT INTO dbo.TARGET_CCI_' + CAST(@table_id AS NVARCHAR(2)) + N' WITH (TABLOCK) SELECT ca.SLOW, ca.INFLATE_GRANT FROM (VALUES (0), (1), (2), (3)) v(x) CROSS APPLY ( SELECT TOP (1048576) sc.SLOW, sc.INFLATE_GRANT FROM SLOW_TO_COMPRESS sc WHERE sc.FOR_SEEKING = v.x ) ca OPTION (MAXDOP 2)'; EXEC sp_executesql @sql; END;
Error code 8645
Batch files that call sqlcmd are a convenient way to kick off lots of queries. For example:
START /B sqlcmd -d TEST -S .\SQL2017RTM -Q "EXEC dbo.INSERT_INTO_TARGET_CCI 1;" > nul START /B sqlcmd -d TEST -S .\SQL2017RTM -Q "EXEC dbo.INSERT_INTO_TARGET_CCI 2;" > nul START /B sqlcmd -d TEST -S .\SQL2017RTM -Q "EXEC dbo.INSERT_INTO_TARGET_CCI 3;" > nul START /B sqlcmd -d TEST -S .\SQL2017RTM -Q "EXEC dbo.INSERT_INTO_TARGET_CCI 4;" > nul START /B sqlcmd -d TEST -S .\SQL2017RTM -Q "EXEC dbo.INSERT_INTO_TARGET_CCI 5;" > nul
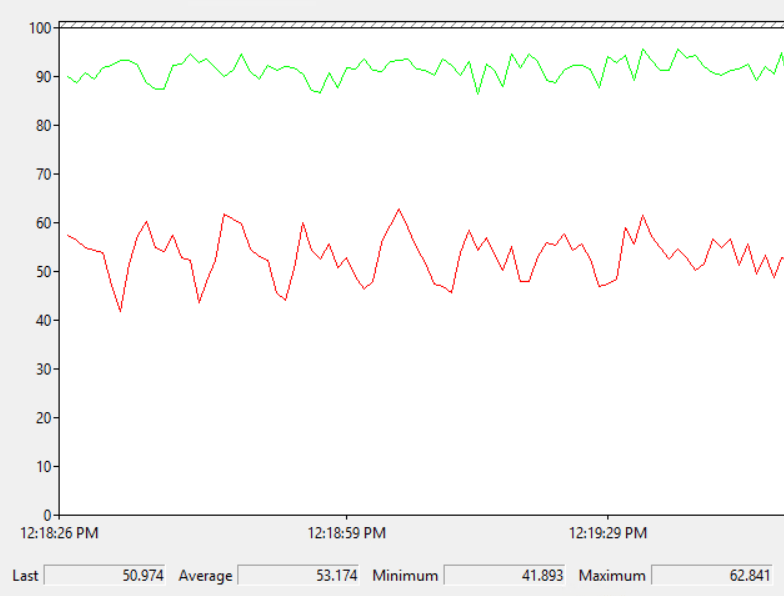
Note that I do not have Resource Governor enabled. If I kick off five queries at once using the batch file I don’t get an error. After 25 seconds two of the five queries are able to execute with the same memory grant as others:

It does make me uncomfortable to see query memory grants exceed the target memory for the semaphore by so much, but at least it’s not over max server memory:

I ran the same test but kicked off a sixth query in SSMS. After 25 seconds I saw the following error for the sixth query:
Msg 8645, Level 17, State 1, Line 1
A timeout occurred while waiting for memory resources to execute the query in resource pool ‘default’ (2). Rerun the query.
I want my lawyer
On SQL Server 2017 CU14 I ran a variety of tests by changing the memory time-out settings at the Resource Governor query level or at the instance level. I tried different Resource Governor pools and even serial queries. I still saw a timeout of 25 seconds no matter what I did. I contacted the attorney that I keep on retainer to help me interpret SQL Server KB articles. Let’s review the relevant text again:
When you try to create a Columnstore Index on a table in Microsoft SQL Server 2016 or 2017, the request may fail after 25 seconds with memory time-out error 8645, depending on how many memory consuming queries are running concurrently and/or how much memory is available at the time of the request. The memory time-out error may occur even when you configure longer memory request time-out at an instance level or at a resource pool level.
He pointed out that the article doesn’t actually say that the time-out is now configurable. Just that it wasn’t configurable in the past. The symptom may strictly describe error 8645. So perhaps the adjustment was very narrow and has to do with avoiding that error only. Fair enough. I ran the same test that say error 8645 on RTM and the sixth query still hit error 8645.
Two of these things aren’t like the others
Let’s kick off five queries on CU14 and take another look at sys.dm_exec_query_memory_grants:

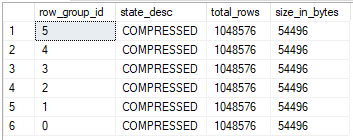
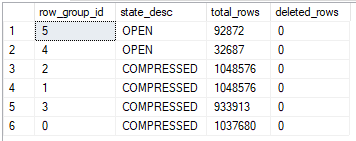
That’s odd. The two queries that hit the 25 second timeout have lower values for max_used_memory_kb than the queries that didn’t time out, even though the memory grants are the same. Looking at sys.dm_db_column_store_row_group_physical_stats for one of the tables with the lower memory grant:
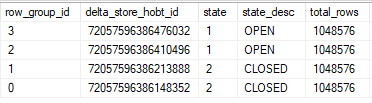
All rows were written to delta stores even though each thread got over 2 million rows. The query still takes its required memory grant but it doesn’t use most of the part reserved for columnstore compression. My best guess is that this is the change described in the KB article. A superficial glance suggests that the internal implementation is the same one used for writing to a delta store in serial:

I think that I can understand the argument for making this change. However, I see intermittent intra-query parallel deadlocks when queries time out in this way:
Msg 1205, Level 13, State 78, Line 1
Transaction (Process ID 61) was deadlocked on lock | communication buffer resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
I’ve also seen this error as well when going too far above target memory:
Msg 701, Level 17, State 123, Line 1
There is insufficient system memory in resource pool ‘default’ to run this query.
Personally, I’d like to see clearly defined behavior that focus on stability. When writing code that does parallel inserts into columnstore indexes it may be desirable to catch errors 8645, 1205, and 701 and to retry the insert after rolling back, perhaps at MAXDOP 1.
Final thoughts
Kb articles for SQL Server fixes can sometimes be misleading because they may focus on how the problem was described in a support ticket even if the scope of the fix or the solution have little to nothing to do with said description. After reading KB article 4480641 you could easily think that error code 8645 no longer occurs with parallel columnstore inserts or that it’s possible to override the 25 second memory timeout for columnstore inserts. Neither one of those is true. Parallel inserts into columnstore tables can still exceed target memory, but they write to multiple delta stores if they hit their 25 second timeout. Thanks for reading!