Sometimes there’s a need to copy tables from one database to another. A large INSERT to copy all of the rows at once may not be desired or possible. For example, if the target database has a recovery model of full we may need to avoid filling the log or long rollbacks if the process needs to be canceled. If the database has a recovery model of simple and there’s a lot of other activity going on we may need to avoid filling the log due to a lengthy transaction. Minimal logging won’t help with that. There may be a desire to throttle each loop with a WAITFOR DELAY command, and so on.
Think of the tables as being copied by a background process. We want to copy them in chunks while efficiently using the server’s resources. It’s not a race to copy all of the data for a particular table as quickly as possible. Also, there many be many tables to move and they could have different structures for their clustered indexes.
Test Data
For the test table I deliberately picked a table far too large to fit into the buffer cache. This wasn’t hard because I configured SQL Server to have the minimum required memory of 1 GB. All tests were conducted with a recovery model of simple. To make things interesting, but not too interesting, I gave the SOURCE_TABLE a two column clustered index:
DROP TABLE IF EXISTS dbo.SOURCE_TABLE; CREATE TABLE dbo.SOURCE_TABLE ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PAGE_TURNER VARCHAR(170) NOT NULL, PRIMARY KEY (ID1, ID2) );
Aiming for a target size of 20 GB, I inserted 100 million rows:
CREATE TABLE #t (ID BIGINT NOT NULL, PRIMARY KEY (ID));
INSERT INTO #t WITH (TABLOCK)
SELECT TOP (10000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2;
INSERT INTO dbo.SOURCE_TABLE WITH (TABLOCK)
SELECT
t1.ID
, t2.ID
, REPLICATE('Z', 170)
FROM #t t1
CROSS JOIN #t t2
ORDER BY t1.ID, t2.ID
OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL);
The table has exactly 20 GB worth of data pages!

Which of course works out to 2.5 million pages. As an aside, I didn’t want to use the temp table to do the data prep but couldn’t find a good way around it. The usual method of spt_values, TOP, and ROW_NUMBER() lead to a pretty large sort. I tried all kinds of tricks but couldn’t make it go away:

The TOP N sort for the outer result set is for the first column of the clustered index. The TOP N sort for the inner result set is for the second column of the clustered index. The final sort before the SELECT is for column 1 and column 2. Clearly, the sort isn’t needed because the data will be already sorted in that order coming out of the join. However, the query optimizer can be very stubborn in these situations.
The code samples in this post are designed to move any table that has a unique, clustered index. If you know something about the data in the table or the structure it may be possible to write more efficient code at the table level. Note that there is no attempted handling of concurrency. If the underlying data in the source table is changing then none of this code should be expected to work. The code can also handle heaps as long as you define a clustered index on them first.
To efficiently use server resources I decided that I wanted to loop in order of the clustered key. This should avoid unnecessary page splitting and lead to a cleaner result table. With the right recovery model, it should also take advantage of reduced logging for all of the inserts in SQL Server 2016. Finally, it would be nice to avoid sorting and excessive tempdb usage. Perhaps many of these jobs will run at once and we don’t want them to fail due to tempdb usage.
Straight Insert
The first thing that I tested was a single INSERT to be used as a benchmark for all of the different algorithms:
INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT * FROM dbo.SOURCE_TABLE WITH (TABLOCK);
This isn’t a fair comparison because we can get better minimal logging for every row, avoid query plan compilations, and we’re simply doing less work overall. However, I think it’s still useful for context and to see how close we can get to the ideal case with no overhead. Here is a table of performance numbers from sys.dm_exec_sessions for our first test:

Full Copy Temp Table
We need to loop over our source table and insert chunks of rows into the target table. One strategy to do this is to insert all of the clustered keys from the source table into a temp table with an IDENTITY column. This approach is easy to understand and the number of keys in the clustered index doesn’t make the SQL more complicated. Here’s one implementation:
DECLARE @total_rows_to_move BIGINT, @batch_size INT = 1000000, @batch_number INT = 1; BEGIN SET NOCOUNT ON; DROP TABLE IF EXISTS #TARGET_TABLE_PKS; CREATE TABLE #TARGET_TABLE_PKS ( ID BIGINT NOT NULL IDENTITY (1, 1), ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID) ); INSERT INTO #TARGET_TABLE_PKS WITH (TABLOCK) (ID1, ID2) SELECT ID1, ID2 FROM dbo.SOURCE_TABLE WITH (TABLOCK) ORDER BY ID1, ID2; SET @total_rows_to_move = @@ROWCOUNT; WHILE @batch_number <= CEILING(@total_rows_to_move / @batch_size) BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) INNER JOIN #TARGET_TABLE_PKS t ON s.ID1 = t.ID1 AND s.ID2 = t.ID2 WHERE t.ID BETWEEN 1 + @batch_size * (@batch_number - 1) AND @batch_size * @batch_number OPTION (RECOMPILE); SET @batch_number = @batch_number + 1; END; DROP TABLE #TARGET_TABLE_PKS; END;
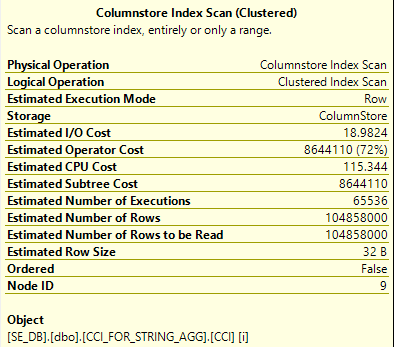
The RECOMPILE hint was included to avoid default estimates caused by the local variables. Even with that, our first attempt does not go so well. The code takes nearly 40 minutes to complete. All performance metrics are bad across the board:

Looking at the query plans, SQL Server chose a merge join between the source table and the temp table:

The merge join won’t always scan every row from the hundred million row table. In fact, the first loop will scan the minimum required number of rows, one million. The next loop scans two million rows, the one after that three million, and so on. The scan can stop early but it always starts with the first row in the table. This strategy is very poorly suited for how we’re processing the table. Performance will be quadratic with the number of loops.
Fix The Join
For this code we know something that the query optimizer doesn’t. A loop join feels like a better choice than merge for this query due to how we’re processing data from the temp table. It’ll do a constant amount of work for each loop. One way to encourage a loop join is to lower the cardinality estimate for the temp table. In the code below I did this by adding a TOP operator and removing the RECOMPILE hint:
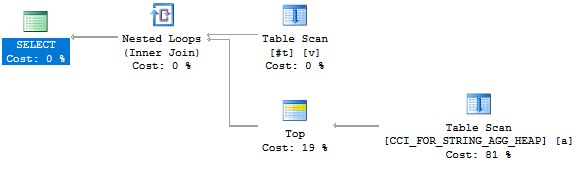
DECLARE @total_rows_to_move BIGINT, @batch_size INT = 1000000, @batch_number INT = 1; BEGIN SET NOCOUNT ON; DROP TABLE IF EXISTS #TARGET_TABLE_PKS; CREATE TABLE #TARGET_TABLE_PKS ( ID BIGINT NOT NULL IDENTITY (1, 1), ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID) ); INSERT INTO #TARGET_TABLE_PKS WITH (TABLOCK) (ID1, ID2) SELECT ID1, ID2 FROM dbo.SOURCE_TABLE WITH (TABLOCK) ORDER BY ID1, ID2; SET @total_rows_to_move = @@ROWCOUNT; WHILE @batch_number <= CEILING(@total_rows_to_move / @batch_size) BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) INNER JOIN ( SELECT TOP (@batch_size) * FROM #TARGET_TABLE_PKS WHERE ID BETWEEN 1 + @batch_size * (@batch_number - 1) AND @batch_size * @batch_number ORDER BY ID ) t ON s.ID1 = t.ID1 AND s.ID2 = t.ID2; SET @batch_number = @batch_number + 1; END; DROP TABLE #TARGET_TABLE_PKS; END;
Now we get a nested loop join because of the default estimate of 100 rows:

As a nice bonus, the unnecessary (from our point of view) sort operator goes away. The data already is in clustered key order due to how we built the temp table. The cardinality estimate for the insert is a bit low, but if the data is already sorted then why should it matter? We see better performance than before:

With the old code we did 100 loops and read an average of 50.5 million rows from the source table. We also read all 100 million rows to build the temp table, so we read a total of 5.15 billion rows from the table. That adds up to a lot of physical reads. With this code we do 100 million index seeks but we only read a total of 200 million rows from the source table. That might be why the logical reads increased so much but physical reads are way down.
Can we improve the code further? Storing all of the clustered keys in a temp table feels like a bit much. It’s a lot of writes and the operation could fail if the table is too large. It would also be nice to not have to read all 100 million rows from the source table using joins.
Sampled Temp Table
There’s no need to store every row from the source table in the temp table. We can instead store a sample of rows and use that sample to build key ranges to perform clustered index range scans against. That should lead to a dramatic reduction in tempdb space usage and makes the joins to the source table unnecessary. One complication is that the SQL to do efficient range scans becomes more annoying to write as the number of clustered key columns increased. For a table with two clustered key columns we can do the following:
WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) )
I’m not doing this technique justice here, but the important part is that all of the filters are seek predicates instead of predicates:

Here’s the full code:
DECLARE @batch_size INT = 1000000, @id1_start BIGINT, @id2_start BIGINT; BEGIN SET NOCOUNT ON; DROP TABLE IF EXISTS #TARGET_TABLE_SAMPLED_PKS; CREATE TABLE #TARGET_TABLE_SAMPLED_PKS ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID1, ID2) ); INSERT INTO #TARGET_TABLE_SAMPLED_PKS SELECT ID1 , ID2 FROM ( SELECT ID1 , ID2 , ROW_NUMBER() OVER (ORDER BY ID1, ID2) RN FROM dbo.SOURCE_TABLE WITH (TABLOCK) ) t WHERE RN % @batch_size = 1; DECLARE cur CURSOR LOCAL FAST_FORWARD FOR SELECT ID1, ID2 FROM #TARGET_TABLE_SAMPLED_PKS ORDER BY ID1, ID2; OPEN cur FETCH NEXT FROM cur INTO @id1_start, @id2_start; WHILE @@FETCH_STATUS = 0 BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT TOP (@batch_size) s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY s.ID1, s.ID2; FETCH NEXT FROM cur INTO @id1_start, @id2_start; END; CLOSE cur; DEALLOCATE cur; DROP TABLE #TARGET_TABLE_SAMPLED_PKS; END;
Performance improves yet again:

However, why is the number of logical reads so high? We’ve eliminated the nested loop joins so this is an unexpected result.
Cardinality Estimates for Inserts
It turns out that the cardinality estimate for inserts can matter after all. DMLRequestSort for the insert operator is set to false. That’s bad when we’re inserting a million of rows at a time. I don’t know the details, but a bad cardinality estimate can cause the wrong internal APIs to be used for inserting the data and logging. We no longer need to reduce the cardinality estimate to get the plan that we want, so let’s try replacing the @batch_size variable with a hardcoded value of 1000000 for the TOP operator. After that change we see another big gain in performance:

The table insert now has the DMLRequestSort property set to true.
No Temp Table
One issue with the code above is that we do a clustered index scan of the entire table at the beginning. Some of that data remains in the buffer cache but very little of it will be useful for the looping part of the procedure. If we can find a way to loop as we need to we may be able to take better advantage of the buffer cache. Also, why use a temp table when you don’t have to?
One way to accomplish this is with the OFFSET keyword introduced in SQL Server 2012. SQL Server always reads and throws away the number of rows specified in the OFFSET clause. It cannot smartly skip ahead in the index. To avoid some of the performance problems with OFFSET we need to use it with an anchor row. Here is an algorithm that uses OFFSET instead of a temp table:
DECLARE @batch_size INT = 1000000, @id1_start BIGINT, @id2_start BIGINT; BEGIN SET NOCOUNT ON; SELECT @id1_start = ID1, @id2_start = ID2 FROM SOURCE_TABLE s WITH (TABLOCK) ORDER BY ID1, ID2 OFFSET 0 ROWS FETCH FIRST 1 ROW ONLY; WHILE @id1_start IS NOT NULL BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT TOP (1000000) s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY s.ID1, s.ID2; SET @id1_start = NULL; SET @id2_start = NULL; SELECT @id1_start = ID1, @id2_start = ID2 FROM SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY ID1, ID2 OFFSET (@batch_size) ROWS FETCH FIRST 1 ROW ONLY; END; END;
OFFSET to get the row that starts the next key range to process. Performance is a bit better than before:

However, the number of physical reads didn’t fall as much as it could have. The source table has 2.5 million data pages and the straight insert only needed 2.5 million physical reads to copy the data, which is hardly a coincidence.
Better Buffer Cache
There’s a subtle issue in the last algorithm. Think about the order of scans and inserts. For the Nth loop we scan one million rows from the source table using the anchor row that we found previously. Nearly all of those rows won’t be in the buffer cache so they will be physical reads. The insert happens at the same time and that certainly has an effect on what will remain in the buffer cache. Then we scan the same range again to find the next anchor row. It feels like it would be better to scan the upcoming range first, get the next anchor row, then perform the insert up to the anchor row. That way data that we want to remain in the buffer cache won’t be kicked out as much by the INSERT. The code to do this is a bit more complex:
DECLARE @batch_size INT = 1000000, @id1_start BIGINT, @id2_start BIGINT, @id1_next BIGINT, @id2_next BIGINT; BEGIN SET NOCOUNT ON; SELECT @id1_start = ID1, @id2_start = ID2 FROM SOURCE_TABLE s WITH (TABLOCK) ORDER BY ID1, ID2 OFFSET 0 ROWS FETCH FIRST 1 ROW ONLY; SELECT @id1_next = ID1, @id2_next = ID2 FROM SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY ID1, ID2 OFFSET (@batch_size) ROWS FETCH FIRST 1 ROW ONLY; WHILE @id1_start IS NOT NULL BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT TOP (1000000) s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY s.ID1, s.ID2; SET @id1_start = @id1_next; SET @id2_start = @id2_next; SET @id1_next = NULL; SET @id2_next = NULL; SELECT @id1_next = ID1, @id2_next = ID2 FROM SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 >= @id2_start) ) ORDER BY ID1, ID2 OFFSET (@batch_size) ROWS FETCH FIRST 1 ROW ONLY; END; END;
However, performance improved yet again. It’s almost like I planned this blog post out in advance!
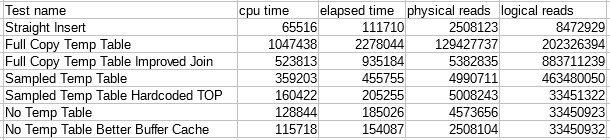
The number of physical reads is now very close to the number required by the straight insert. Note that we could have also reduced the physical read count of the previous algorithm by lowering the batch size.
The Single Source Scan Method
What if we don’t want to read the source table twice? After all, the straight insert only needs to read the source table once. We can’t let SQL Server outsmart us that much. The key to this next algorithm is that the target table starts out empty. Since we’re inserting in clustered key order, getting the next anchor for a loop is as simple as selecting the last clustered key from the target table and changing the predicate a little bit:
DECLARE @batch_size INT = 1000000, @RC int, @id1_start BIGINT, @id2_start BIGINT; BEGIN SET NOCOUNT ON; INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT TOP (1000000) s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) ORDER BY s.ID1, s.ID2; set @RC = @@ROWCOUNT; SELECT TOP (1) @id1_start = ID1, @id2_start = ID2 FROM TARGET_TABLE s WITH (TABLOCK) ORDER BY ID1 DESC, ID2 DESC; WHILE @RC = @batch_size BEGIN INSERT INTO dbo.TARGET_TABLE WITH (TABLOCK) SELECT TOP (1000000) s.* FROM dbo.SOURCE_TABLE s WITH (TABLOCK) WHERE ( s.ID1 > @id1_start OR (s.ID1 = @id1_start AND s.ID2 > @id2_start) ) ORDER BY s.ID1, s.ID2; set @RC = @@ROWCOUNT; SELECT TOP (1) @id1_start = ID1, @id2_start = ID2 FROM TARGET_TABLE s WITH (TABLOCK) ORDER BY ID1 DESC, ID2 DESC; END; END;
We see a minor improvement in the number of logical reads as expected:

This was the best algorithm that I was to come up with.
A Few Bad Ideas
I played around with a few other methods of moving the data and feel the need to caution the reader against them. One idea is to define an AFTER INSERT trigger on the target table and to use the special inserted table to save off the value of the last clustered key inserted into that table. This appeared to just be slower than the single scan method and who wants to use triggers when they can be avoided?
A standard cursor performs extremely poorly because it operators on one row at a time. There’s an impressively poorly-documented alternative called API cursors which can process more than one row at a time. After some struggling I was able to use API cursors to copy data from one table to the other, but there was an intermediate step that loaded data from the cursor into a hidden temp table. Also, the cardinality estimate from the insert came from an EXECUTE and was a single row. Performance was very poor.
Final Thoughts
The point of this post wasn’t to insist that one method of moving data is better than all others. In fact, many different algorithms will be likely be suitable depending on the table structure, table size, and time requirements. However, it’s important to know that seemingly minor changes can lead to large differences in performance when moving around data that cannot fit in the buffer pool. These performance problems can become magnified when moving large tables or lots of tables. Thanks for reading!