Auto soft-NUMA can lead to increased SOS_SCHEDULER_YIELD waits on large systems with limited concurrency of large parallel queries. This blog post contains a reproduction of the issue and a brief analysis. I hope any readers from Microsoft appreciate my restraint in not making an “It Just Runs Slower” joke.
What is Auto Soft-NUMA?
Auto soft-NUMA was released in SQL Server 2016 and it is automatically turned on. However, it only has an effect if SQL Server is able to detect that a socket has 9 or more cores. The documentation isn’t very precise in some places and is outright misleading in others, but the Microsoft docs page is a good starting point for readers not familiar with it. For a very quick summary, schedulers in a memory node are split into soft-NUMA groups depending on the total number of schedulers and whether or not SQL Server can detect hyperthreading.
Microsoft expects auto soft-NUMA to improve scalability and performance for most workloads. They don’t really explain this idea in detail, but they do talk about how certain internal structures are partitioned by soft-NUMA node and that partitioning can be helpful for large systems.
This might not be what they mean, but there is one LOG WRITER system process per soft-NUMA node on SQL Server 2016 up to a maximum of 4. All of the log writers aren’t spread over multiple NUMA nodes though. To give an example, a single socket 32 core server will have one log writer process without auto soft-NUMA. With auto soft-NUMA there will be four soft-NUMA nodes, and as a consequence, four log writer processes on CPUs 1-4. That might be beneficial for some workloads.
Another observable behavior change caused by soft-NUMA nodes is differences in scheduling. The effect on scheduler assignment for MAXDOP 1 queries is well-known, but there are more subtle issues that can arise when running parallel queries.
The Test Server
The test server was a VM with 96 cores on four physical NUMA nodes. The VM was the only guest on the physical host and the virtual layout matched the physical layout. Within SQL Server, there are 96 schedulers and 4 memory nodes. Each memory node is split into 3 soft-NUMA nodes of 8 schedulers because SQL Server can’t tell if hyperthreading is enabled and 8 divides evenly into 24. Here’s the output of sys.dm_os_nodes with auto soft-NUMA enabled:
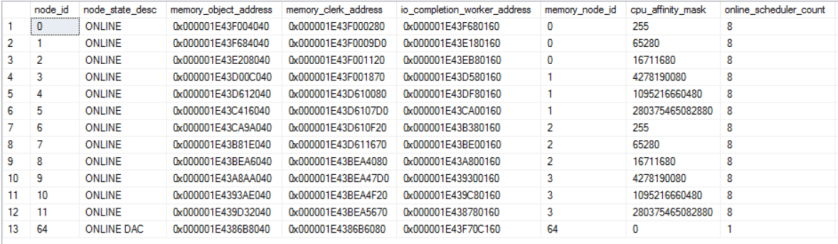
Server MAXDOP is set to 8. In theory, this should be the ideal setup. Microsoft says that they find eight to be the magic number when it comes to scalabilty of parallel processes. If auto soft-NUMA is disabled then there are only four NUMA nodes with one for each memory node. Here’s the output of sys.dm_os_nodes with auto soft-NUMA disabled:

The Test Code
For the test code, I wanted an easy way to alternate sets of parallel queries that finish very quickly with parallel queries that take a long time to finish. I ended up creating a simple stored procedure that only uses the spt_values table and kicks off a user-specified number of parallel queries that finish nearly instanteously followed by a query that cross joins millions of rows together. The final query in the procedure won’t finish in a reasonable amount of time. it is designed to be cancelled. The idea here is to give the observer as much time as needed to poke around various DMVs to make notes about how threads were scheduled.
CREATE OR ALTER PROCEDURE [dbo].[RUN_SET_OF_QUERIES] (@num_cheap_queries INT) AS BEGIN SET NOCOUNT ON; DECLARE @dummy INT, @queries_run_so_far INT = 0, @filter INT = 0; WHILE @queries_run_so_far BETWEEN 0 AND @num_cheap_queries - 1 BEGIN SELECT @dummy = MAX(t1.high + t2.high) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 WHERE @filter = 1 OPTION (MAXDOP 8); SET @queries_run_so_far = @queries_run_so_far + 1; END; SELECT @dummy = MAX(t1.high + t2.high + t3.high + t4.high) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 CROSS JOIN master..spt_values t4 OPTION (MAXDOP 8); END;
To that end, I chose to execute the stored procedure through sqlcmd. The expensive queries don’t modify data so it’s very fast to cancel all of the in-progress queries by closing the sqlcmd window. Readers following along with their 96 core servers at home should feel free to use whatever methodology they wish to kick off the stored procedures. I found it important to be able to kick off the stored procedure with a user-defined time delay between executions and to not have to wait on the completion of the stored procedure before sending more queries. Below is example syntax for a batch file which kicks off four stored procedure calls with a delay of about 2.5 seconds between each call. Each stored procedure executes two fast parallel queries before executing the very expensive one.
START /B sqlcmd -d {{db_name}} -S {{server_name}} -Q "EXEC [dbo].[RUN_SET_OF_QUERIES] @num_cheap_queries=2" > nul
ping 192.2.0.1 -n 1 -w 2500 > nul
START /B sqlcmd -d {{db_name}} -S {{server_name}} -Q "EXEC [dbo].[RUN_SET_OF_QUERIES] @num_cheap_queries=2" > nul
ping 192.2.0.1 -n 1 -w 2500 > nul
START /B sqlcmd -d {{db_name}} -S {{server_name}} -Q "EXEC [dbo].[RUN_SET_OF_QUERIES] @num_cheap_queries=2" > nul
ping 192.2.0.1 -n 1 -w 2500 > nul
START /B sqlcmd -d {{db_name}} -S {{server_name}} -Q "EXEC [dbo].[RUN_SET_OF_QUERIES] @num_cheap_queries=2" > nul
ping 192.2.0.1 -n 1 -w 2500 > nul
Finally, I needed a query to examine the distribution of parallel workers on the system. In general, you want your parallel workers to be spread out enough so that all schedulers are able to do some useful work. I used the following to get an idea of parallel worker distribution:
SELECT session_id , dop , start_time , request_scheduler_id , STRING_AGG ( CASE WHEN exec_context_id = 0 THEN NULL ELSE scheduler_id END , ',' ) WITHIN GROUP (ORDER BY scheduler_id) AS used_schedulers_for_parallel_workers FROM ( SELECT dot.session_id , dot.scheduler_id , dot.exec_context_id , req.scheduler_id AS request_scheduler_id , req.command , req.dop , req.start_time , dos.parent_node_id , dos.cpu_id , dos.is_idle , dos.load_factor , dos.active_workers_count FROM ( SELECT DISTINCT session_id , scheduler_id , exec_context_id FROM sys.dm_os_tasks ) dot LEFT OUTER JOIN sys.dm_exec_requests req ON dot.session_id = req.session_id AND req.request_id = 0 LEFT OUTER JOIN sys.dm_exec_sessions ses ON dot.session_id = ses.session_id LEFT OUTER JOIN sys.dm_os_schedulers dos ON dos.scheduler_id = dot.scheduler_id WHERE ses.is_user_process = 1 ) t GROUP BY session_id , dop , start_time , request_scheduler_id ORDER BY start_time OPTION (MAXDOP 1);
This query is lazy in that it doesn’t handle plans with multiple parallel zones correctly. However, it works well enough for tests on simple parallel queries (such as the ones for the reproduction forthis post) or for properly written batch mode queries.
Testing with Auto Soft-NUMA
As a reminder, with auto soft-NUMA on my server I had 12 soft-NUMA nodes of 8 schedulers. I restarted SQL Server and ran a .bat file with the following commands repeated 12 times:
START /B sqlcmd -d {{db_name}} -S {{server_name}} -Q "EXEC [dbo].[RUN_SET_OF_QUERIES] @num_cheap_queries=2" > nul
ping 192.2.0.1 -n 1 -w 2500 > nul
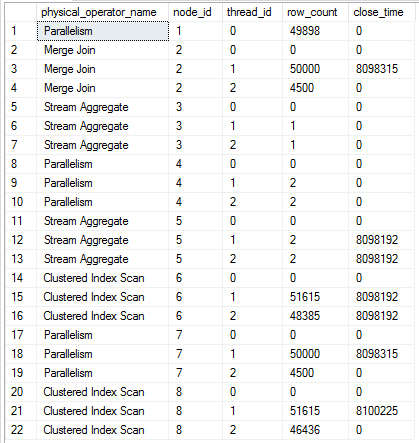
In other words, I kicked off a total of 24 very fast parallel queries and 12 very long running parallel queries. Here is how my scheduling of parallel workers looked:

That is a pretty bad outcome. I have 12 MAXDOP 8 queries with all parallel workers assigned to schedulers on just four NUMA nodes. Each CPU in those NUMA nodes has the equivalent of 300% work assigned to it. Execution context 0 doesn’t do much work for the test query, so I have 64 cpus with barely any work to do. It’s unlikely that server CPU will go much higher than 33%. Here are wait stats after running the workload for two minutes:

We accumulated two hours of SOS_SCHEDULER_YIELD waits in just two minutes. Not what you want to see with a server that’s around 33% CPU utilization. What went wrong?
Mo’ Schedulers Mo’ Problems
Scheduling of parallel queries was changed in SQL Server 2012. Bob Dorr blogged about it here, and it’s the best source that I’m aware of. Even so, I’ve had a lot of trouble figuring out exactly what the words in that blog post mean. Readers of this blog may be able to relate. I’ve only ever observed the spread selection type in practice, so the most relevant part of the linked post is this one:
Spread: This is the most common decision made by SQL Server. The decision spreads the workers across multiple nodes as required. The design is similar to full except the starting position is based on the saved, next node, global enumerator.
Consider a server with soft-NUMA nodes of 8 schedulers with MAXDOP 8. The first parallel query will be sent to numa node 0. The number of active workers matches the number of schedulers exactly so each active worker is assigned to a different scheduler in the NUMA node. The second parallel query will be sent to NUMA node 1. The third parallel query will be sent to NUMA node 2, and so on. Execution of serial queries or creation of sessions does not matter. That advances a counter that’s separate from the “global enumerator” used for parallel query scheduler placement. As far as I can tell the scheduler assigned to execution context 0 does not affect the scheduling of the parallel worker threads, although it can certainly affect parallel query performance.
The scenario described above doesn’t sound so bad. It can work well if the parallel queries take roughly about the same amount of time to complete and query MAXDOP matches the number of schedulers per soft-NUMA node. Problems can emerge when at least one of those is not true. With the spread selection type it’s possible that the amount of work already assigned to schedulers has no effect on parallel query scheduler placement. Let that sink in. You could have 100 serial queries all assigned to schedulers in numa node 0 but SQL Server may still send a parallel query to that NUMA node. It depends on the position of the “global enumerator” as opposed to current work on the server.
That behavior is why the reproduction in this post works. With a total of 12 soft-NUMA nodes all I need to do is run queries in a fast-fast-slow pattern to cause the slow queries to be doubled and tripled up on schedulers. In some cases sending more parallel queries to a server can be a valid strategy if server CPU isn’t quite as high as you’d like. That might not work here though. Sending more queries will mostly just rack up additional SOS_SCHEDULER_YIELD waits.
It isn’t true that SQL Server never considers the amount of work on a scheduler when assigning parallel worker threads. NUMA nodes have limits on the number of parallel workers as can be seen in sys.dm_exec_query_parallel_workers. There appears to be scheduling choices which consider load factor or worker count when the set of parallel workers only fills part of a soft-NUMA node. Consider a pair of MAXDOP 12 queries running on the same server as described earlier. Suppose that the “global enumerator” starts at position 0. The first query will grab 8 schedulers from NUMA node 0 and 4 schedulers from NUMA node 1. SQL Server has some choice about which schedulers it grabs from NUMA node 1. However, there is no choice to be made for NUMA node 0 because it grabs all of them. The second parallel query grabs 4 schedulers from NUMA node 1 and 8 schedulers from NUMA node 2. Again, SQL server can make a choice about which schedulers it uses from NUMA node 1. That decision can factor in system load. Just like with serial queries, if queries are sent too quickly to the server then you might see unnecessary doubling up of schedulers in NUMA node 1.
I didn’t try to dig into the details fully, but hopefully the above gives you a high level understanding of what kind of problems you might see with parallel query scheduling on servers with more than one NUMA node.
Testing Without Auto Soft-NUMA
Armed with our new knowledge, let’s consider what might happen with the previous workload if auto soft-NUMA is disabled. Assume that the server was restarted and the global enumerator starts at position 0. Three MAXDOP 8 queries are able to fit into each NUMA node of 24 schedulers. The expensive query for the first execution of the stored procedure will be sent to schedulers on the first NUMA node. The expensive query for the second execution of the stored procedure will be sent to schedulers on the second NUMA node, the third will be sent to the third NUMA node, and the fourth will be sent to the fourth NUMA node. As we continue to execute more queries we’ll loop around but the key difference is that SQL Server is able to place the parallel worker threads however it wants on the 24 schedulers. It can look at things like load factor or the number of workers per scheduler. After all 12 stored procedures have started we can end up with scheduling like this:

Every scheduler has at least one thread for a parallel worker or an execution context 0 thread. Scheduler 22 is one of eight schedulers with more than one parallel worker assigned. Execution context 0 for these queries is expected to do very little work, so it could be argued that a better distribution would be to have exactly one parallel worker per scheduler. However, overall this is a pretty good distribution and we can push server CPU to 90%. After two minutes of execution we have significantly fewer time spent on SOS_SCHEDULER_YIELD waits compared to before:

In this situation, we can see a significant improvement in server resource utilization by disabling auto soft-NUMA. For other workloads and query mixes the scheduling behavior offered with auto soft-NUMA may be a better fit. Key factors include the patttern of parallel queries, MAXDOP, and the number of schedulers per memory node.
Final Thoughts
We observed a bottleneck with SOS_SCHEDULER_YIELD waits for an ETL workload for which it was not easy to scale up the number of queries. This can happen if there are only so many partitions to process or if ETL queries require large memory grants, say, for compressing columnstore data. We were able to shave 30% off the overall workload time by using Resource Governor CPU affinity and doing our own scheduling. Less drastic workarounds include disabling auto soft-NUMA, changing MAXDOP, increasing CTFP, or reigning in some queries which don’t need to run in parallel. Thanks for reading!