Aggregate pushdown is an optimization for aggregate queries against columnstore tables that was introduced in SQL Server 2016. Some aggregate computations can be pushed to the scan node instead of calculated in an aggregate node. I found the documentation to be a little light on details so I tried to find as many restrictions around the functionality as I could through testing.
Test Data
Most of my testing was done against a simple CCI with a single compressed rowgroup:
DROP TABLE IF EXISTS dbo.AP_1_RG; CREATE TABLE dbo.AP_1_RG ( ID1 bigint NULL, ID2 bigint NULL, AGG_COLUMN BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.AP_1_RG WITH (TABLOCK) SELECT t.RN % 8000 , t.RN % 8000 , 0 FROM ( SELECT TOP (1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t OPTION (MAXDOP 1);
I found this table structure and data to be convenient for most of the test cases, but all tests can be reproduced with different data or a different table structure.
Restrictions without GROUP BY
Aggregate pushdown is supported both with and without a GROUP BY clause. I found it convenient to test those two cases separately. Below is a list of restrictions that I found or verified during testing.
Data Type of Aggregate Column
The documentation says:
Any datatype <= 64 bits is supported. For example, bigint is supported as its size is 8 bytes but decimal (38,6) is not because its size is 17 bytes. Also, no string types are supported.
However, this isn’t quite accurate. Float data types are not supported. numeric(10,0) is supported despite requiring 9 bytes for storage. Here’s a full table of results:
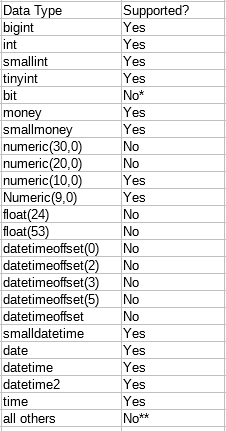
* bit is not supported for aggregates in general
** not all data types were tested
I would summarize support as all date and time data types are supported except datetimeoffset. All exact numeric data types are supported if they are under 10 bytes. Approximate numerics, strings, and other data types are not supported.
Data Type Conversions
Aggregate pushdown does not appear to be supported if there is any data type conversion in any part of the aggregate expression. Both implicit and explicit data type conversions can cause issues, although it ultimately depends on the rules for data type precedence and if the query optimizer determines if a conversion is needed. For example, the following queries are eligible for pushdown:
SELECT MAX(ID1 + 1) FROM dbo.AP_1_RG; SELECT MAX(ID1 + CAST(1 AS BIGINT)) FROM dbo.AP_1_RG; SELECT MAX(ID1 + CAST(1 AS INT)) FROM dbo.AP_1_RG; SELECT SUM(ID1 + 1) FROM dbo.AP_1_RG; SELECT SUM(1 * ID1) FROM dbo.AP_1_RG; SELECT MAX(CAST(ID1 AS BIGINT)) FROM dbo.AP_1_RG;
However, the following queries are not:
SELECT MAX(CAST(ID1 AS INT)) FROM dbo.AP_1_RG; SELECT SUM(1.5 * ID1) FROM dbo.AP_1_RG; SELECT SUM(ID1 + CAST(1 AS BIGINT)) FROM dbo.AP_1_RG;
Sometimes the compute scalar appears with the conversion even when we might not expect it, like for the last query:
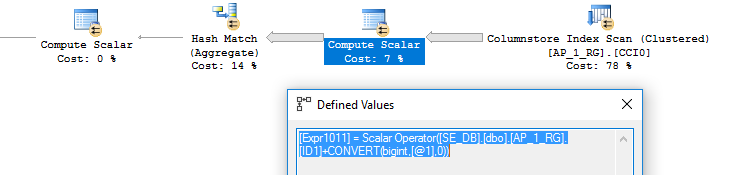
Unsupported Operators
Division and modulus prevent aggregate pushdown even when they wouldn’t change the result or if there isn’t a data type conversion in the plan. There are likely other unsupported operators as well. The following queries are eligible for pushdown:
SELECT MAX(ID1 + 1) FROM dbo.AP_1_RG; SELECT MAX(ID1 - 1) FROM dbo.AP_1_RG; SELECT MAX(ID1 * 2) FROM dbo.AP_1_RG;
The following queries are not eligible for pushdown:
SELECT MAX(ID1 / 1) FROM dbo.AP_1_RG; SELECT MAX(ID1 % 9999999999999) FROM dbo.AP_1_RG;
Aggregate Cannot be Applied to Scan
The aggregate expression must be applied directly to the scan. If there’s a filter between the aggregate and the scan then it won’t work. A compute scalar node between the aggregate and the scan can be okay.
Filter expressions involving OR on different columns tend to be calculated as a filter. This means that the following query isn’t eligible for pushdown:
SELECT MIN(ID1) FROM dbo.AP_1_RG WHERE ID1 > 0 OR ID2 > 0;
It’s likely that this restriction will affect many queries with joins to other tables.
Local Variables Without PEO
Aggregate pushdown is not available if there is a local variable in the aggregate expression unless the optimizer is able to embed the literal parameter value in the query, such as with a RECOMPILE hint. For example, the first query is not eligible for pushdown but the second query is:
DECLARE @var BIGINT = 0; -- no SELECT MIN(ID1 + @var) FROM dbo.AP_1_RG; -- yes SELECT MIN(ID1 + @var) FROM dbo.AP_1_RG OPTION (RECOMPILE);
Trivial Plans
Simple queries that use SUM, AVG, COUNT, or COUNT_BIG against very small tables may get a trivial plan. In SQL Server 2016 that trivial plan will not be eligible for batch mode so aggregate pushdown will not occur. Consider the following CCI with 10000 rows in a compressed rowgroup:
DROP TABLE IF EXISTS AGG_PUSHDOWN_FEW_ROWS; CREATE TABLE dbo.AGG_PUSHDOWN_FEW_ROWS ( ID BIGINT NOT NULL, INDEX CCI2 CLUSTERED COLUMNSTORE ); INSERT INTO dbo.AGG_PUSHDOWN_FEW_ROWS WITH (TABLOCK) SELECT t.RN FROM ( SELECT TOP (10000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ) t OPTION (MAXDOP 1); ALTER INDEX CCI2 ON AGG_PUSHDOWN_FEW_ROWS REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
With the default cost threshold for parallelism value of 5 I get a trivial plan:
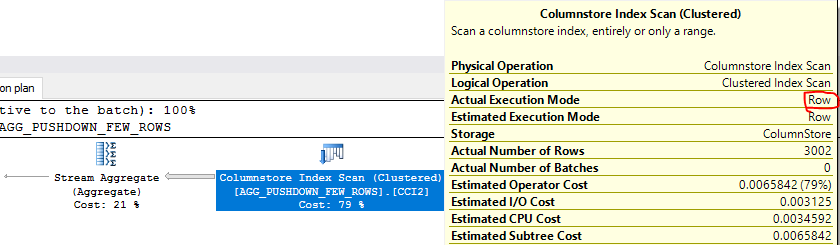
If I decrease the CTFP value to 0 I get batch mode along with aggregate pushdown. As far as I can tell, queries with MAX or MIN do not have this issue.
Lack of Hash Match
For some queries the query optimizer may cost a stream aggregate as a cheaper alternative to a hash match aggregate. Aggregate pushdown is not available with a stream aggregate. If I truncate the AGG_PUSHDOWN_FEW_ROWS table and load 3002 rows into it I get a stream aggregate and no pushdown. With 3003 rows I get a hash match and pushdown. The tipping point depends on the aggregate function, MAXDOP, the data loaded into the table, and so on. The undocumented query hint QUERYRULEOFF GbAggToStrm can be used to encourage a hash match aggregate. If the aggregated column is a string this gets more complicated.
Non-trivial CASE statements
Trivial CASE statements inside the aggregate are still eligible for pushdown:
SELECT SUM(CASE WHEN 1 = 1 THEN ID1 ELSE ID2 END) FROM dbo.AP_1_RG;
However, many other CASE statements are not. Here is one example:
SELECT SUM(CASE WHEN ID1 < ID2 THEN ID1 ELSE ID2 END) FROM dbo.AP_1_RG;
Basic Restrictions
For completeness I’ll list a few more of the more obvious restrictions on pushdown. Many of these are documented by Microsoft. The CCI must contain at least one compressed rowgroup. Delta stores are not eligible for pushdown. There are only six aggregate functions supported: COUNT, COUNT_BIG, MIN, MAX, SUM, and AVG. COUNT (DISTINCT col_name) is not supported.
If a query does not get batch mode due to TF 9453 or for other reasons it will not get aggregate pushdown. Undocumented trace flag 9354 directly disables aggregate pushdown.
Restrictions with GROUP BY
Queries with a GROUP BY have many, if not, all of the same restrictions on the aggregate expressions. As far as I can tell there are no restrictions on the data type of the GROUP BY columns. More than one GROUP BY column is supported as well. However, there are a few restrictions which only apply to queries with a GROUP BY clause.
Non-direct Column References
The columns in the GROUP BY need to be columns. Adding scalars and other nonsense appears to make the query ineligible. The following queries are not eligible:
SELECT ID1 + 0, SUM(AGG_COLUMN) FROM dbo.AP_1_RG GROUP BY ID1 + 0; SELECT ID1 + ID2, SUM(AGG_COLUMN) FROM dbo.AP_1_RG GROUP BY ID1 + ID2;
This one is eligible:
SELECT ID1, ID2, SUM(AGG_COLUMN) FROM dbo.AP_1_RG GROUP BY ID1, ID2;
Segment Not Compressed Enough?
A rowgroup appears to be ineligible for aggregate pushdown if the GROUP BY column has a segment size which is too large. This can be observed with the following test data:
DROP TABLE IF EXISTS AP_3_RG; CREATE TABLE dbo.AP_3_RG ( ID1 bigint NULL, AGG_COLUMN BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.AP_3_RG WITH (TABLOCK) SELECT t.RN % 16000 , 0 FROM ( SELECT TOP (1 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ) t OPTION (MAXDOP 1); INSERT INTO dbo.AP_3_RG WITH (TABLOCK) SELECT t.RN % 17000 , 0 FROM ( SELECT TOP (1 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ) t OPTION (MAXDOP 1); INSERT INTO dbo.AP_3_RG WITH (TABLOCK) SELECT t.RN % 16000 , 0 FROM ( SELECT TOP (1 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ) t OPTION (MAXDOP 1);
Rows from the second rowgroup are not locally aggregated for the following query:
SELECT ID1, SUM(AGG_COLUMN) FROM AP_3_RG GROUP BY ID1 OPTION (MAXDOP 1);
The following query has 2097152 locally aggregated rows which correspond to the first and third rowgroups. From the actual plan:

Poking around in the sys.column_store_segments and sys.column_store_dictionaries DMVs doesn’t reveal any interesting differences other than the rowgroup with more distinct values has a much larger size (2097736 bytes versus 128576 bytes ). We can go deeper with the undocumented DBCC CSINDEX:
DBCC TRACEON (3604); DBCC CSINDEX ( 7, -- DB_ID 72057613148028928, -- hobt_id 2, -- 1 + column_id 0, -- segment_id 1, -- 1 for segment 0 -- print option );
Among other differences, for the 16000 distinct value segment we see:
Bitpack Data Header:
Bitpack Entry Size = 16
Bitpack Unit Count = 0
Bitpack MinId = 3
Bitpack DataSize = 0
But for the 17000 distinct value segment we see:
Bitpack Data Header:
Bitpack Entry Size = 16
Bitpack Unit Count = 262144
Bitpack MinId = 3
Bitpack DataSize = 2097152
Perhaps bitpack compressed data is not eligible for aggregate pushdown?
It’s important to note that segments are not compressed independently in SQL Server, despite the data being stored at a column level. For the AP_1_RG table we’re eligible for pushdown when aggregating by ID1 or ID2. However, if I truncate the table and change the data slightly:
TRUNCATE TABLE dbo.AP_1_RG; INSERT INTO dbo.AP_1_RG WITH (TABLOCK) SELECT t.RN % 8000 , t.RN % 8001 -- was previously 8000 , 0 FROM ( SELECT TOP (1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ) t OPTION (MAXDOP 1);
Now both columns are no longer eligible for aggregate pushdown. A REBUILD operation on the table does not help. Tricking SQL Server into assigning more memory to the columnstore compression also does not help.
Pushdown Surprises
During testing I was surprised by a few queries that supported aggregate pushdown. The most surprising was that the following query can get aggregate pushdown:
SELECT MAX(ID + ID2) FROM dbo.AP_1_RG;
I have no idea how it works, but it does. For a few others, TABLESAMPLE does not prevent aggregate pushdown from happening. In addition, GROUP BY CUBE, GROUPING SETS, and ROLLUP are supported as well.
Changes with SQL Server 2017
I ran the same series of tests on SQL Server 2017 RC1. The only difference I observed was that I could no longer get a trivial plan without batch mode aggregation. This change was announced here by Microsoft.
Final Thoughts
As you can see, there are many undocumented restrictions around aggregate pushdown. These limits may be changed or go away as Microsoft continues to update SQL Server. Pushdown with GROUP BY is supported for some queries against some tables, but eligibility appears to be based on how the data is compressed, which cannot be predicted ahead of time. In my opinion, this makes it rather difficult to count on in practice. Thanks for reading!
