I’m the kind of guy who sometimes likes to look at execution plans with different hints applied to see how the plan shape and query operator costs change. Sometimes paying attention to operator costs can provide valuable clues as to why the query optimizer selected a plan that you didn’t like. Sometimes it doesn’t. My least favorite scenario is when I see inconsistent operator costs. This blog post covers a reproduction of such a case involving the dreaded and feared row goal.
The Data
For the data in my demo tables, I wanted a query of the following form:
SELECT *
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
);
that returned zero rows. However, I wanted the query optimizer to think that a decent number of rows would be returned. This was more difficult to do than expected. I could have just hacked stats to easily accomplish what I wanted, but did not do so out of stubbornness and pride. I eventually found a data set through trial and error with a final cardinality estimate of 16935.2 rows, or 1.7% of the rows in the outer table:
DROP TABLE IF EXISTS dbo.OUTER_HEAP; CREATE TABLE dbo.OUTER_HEAP ( ID VARCHAR(10) ); INSERT INTO dbo.OUTER_HEAP WITH (TABLOCK) SELECT TOP (1000000) 1500000 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); CREATE STATISTICS S1 ON dbo.OUTER_HEAP (ID) WITH FULLSCAN; DROP TABLE IF EXISTS dbo.INNER_CI; CREATE TABLE dbo.INNER_CI ( ID VARCHAR(10), PRIMARY KEY (ID) ); INSERT INTO dbo.INNER_CI WITH (TABLOCK) SELECT TOP (2000000) 500000 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); CREATE STATISTICS S1 ON dbo.INNER_CI (ID) WITH FULLSCAN;
The actual query of interest is the following one:
SELECT TOP (1) 1
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
);
Such a query might be used as part of an ETL process as some kind of data validation step. The most interesting case to me is when the query returns no rows, but the query optimizer (for whatever reason) thinks otherwise.
Row Goal Problems
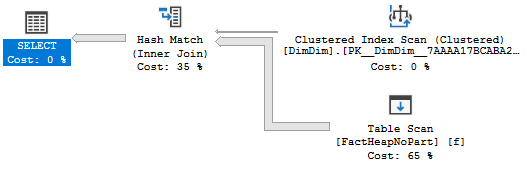
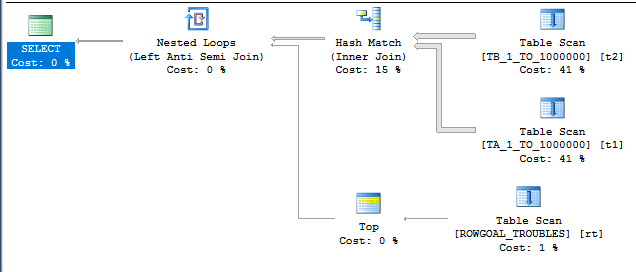
On my machine I get the following plan for the TOP (1) query:

The plan has a total cost of 0.198516 optimizer units. If you know anything about row goals (this may be a good time for the reader to visit Paul White’s series on row goals) you might not be terribly surprised by the outcome. The row goal introduced by the TOP (1) makes the nested loop join very attractive in comparison to other plan choices. The cost of the scan on OUTER_HEAP is discounted from 2.93662 units to 0.0036173 units and the optimizer only expects to do 116 clustered index seeks against INNER_CI before it finds a row that does not match. However, we know our data and we know that all rows match. Therefore, the query will not return any rows and it must scan all rows in OUTER_HEAP if I execute the query. On my machine the query takes about two seconds:
CPU time = 1953 ms, elapsed time = 1963 ms.
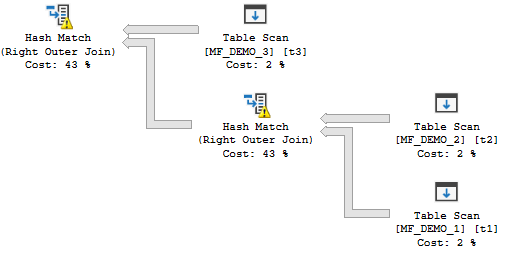
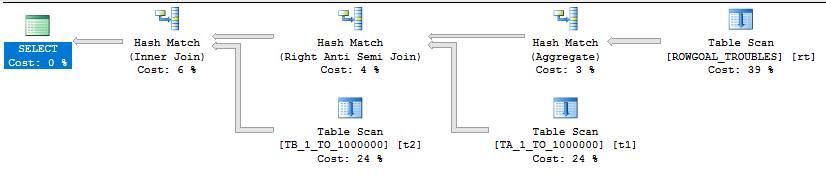
If we’re going to read most of the rows anyway why not try a HASH JOIN hint? At least that plan won’t have a million clustered index seeks:

The new plan runs in MAXDOP 4 on my machine (although for not very long due to CPU cooling issues) and has a total cost of 19.9924 optimizer units. Query execution finishes in significantly less time:
CPU time = 1187 ms, elapsed time = 372 ms.
The Riddle
Can we do better than an ugly join hint? Microsoft blessed us with USE HINT functionality in SQL Server 2016 SP1, so let’s go ahead and try that to see if we can improve the performance of the query. To understand the full effect of the hint let’s get estimated plans for OPTION clauses of (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL'), LOOP JOIN) and (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL'), HASH JOIN). In theory, that will make it easy to compare the two queries:
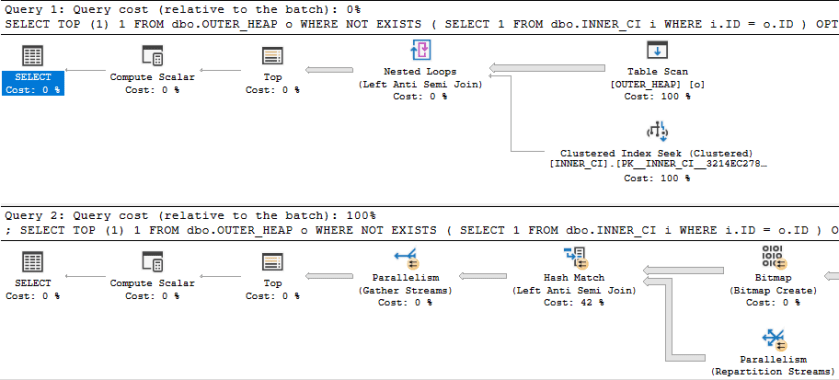
Something looks very wrong here. The loop join plan has a significantly lower cost than the hash join plan! In fact, the loop join plan has a total cost of 0.0167621 optimizer units. Why would disabling row goals for such a plan cause a decrease in total query cost?
I uploaded the estimated plans here for those who wish to examine them without going through the trouble of creating tables.
Let’s Try Adding Trace Flags
First let’s try the query with just a USE HINT and no join hint. I get the hash join plan shape that I was after with a total cost of 19.9924 optimizer units. That’s definitely a good thing, but why did the optimizer pick that plan? The plan with a loop join is quite a bargain at 0.0167621 optimizer units. The optimization level is FULL, but that doesn’t mean that every possible plan choice was evaluated. Perhaps the answer is as simple as the optimizer did not consider a nested loop join plan while evaluating possible plan choices.
There are a few different ways to see which optimizer rules were considered during query plan compilation. We can add trace flags 3604 and 8619 at the query level to get information about the rules that were applied during optimization. All of these trace flags are undocumented, don’t use them in production, blah blah blah. For clarity, the query now looks like this:
SELECT TOP (1) 1
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
) OPTION (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL')
, QUERYTRACEON 3604
, QUERYTRACEON 8619
);
Among other rules, we can see a few associated with nested loops:
Apply Rule: LeftSideJNtoIdxLookup - LOJN/LSJ/LASJ -> IDX LOOKUP Apply Rule: LASJNtoNL - LASJN -> NL
So the optimizer did consider nested loop joins at some point but it went with the hash join plan instead. That’s interesting.
Let’s Try More Trace Flags
A logical next step is to try to get more operator costing information. Perhaps the cost of the nested loop join plan when considered during optimization is different from the value displayed in the query plan in SSMS. As the optimizer applies different rules and does different transformations the overall cost can change, so I suppose this isn’t a totally unreasonable theory. My first attempt at getting cost information for multiple plan options is by looking at the final memo for the query. This can be done with trace flag 8615.
For clarity, the query now looks like this:
SELECT TOP (1) 1
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
) OPTION (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL')
, QUERYTRACEON 3604
, QUERYTRACEON 8615
-- , QUERYTRACEON 8619
);
Group 8 is the only one with any costing information for joins:
Group 8: Card=16935.2 (Max=1.1e+006, Min=0) 11 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.9 7.10 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 26.5569 (Distance = 1) 4 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.4 7.3 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 38.4812 (Distance = 1) 1 LogOp_RightAntiSemiJoin 7 6 5 (Distance = 1) 0 LogOp_LeftAntiSemiJoin 6 7 5 (Distance = 0)
This is rather disappointing. There’s only costing information for a few hash join plans. We know that other join types were considered. Perhaps they were discarded from the memo. The final memo just doesn’t have enough information to answer our question.
We Must Not Be Using Enough Trace Flags
There’s a trace flag that adds memo arguments to trace flag 8619: 8620. Perhaps that will give us additional clues. For clarity, the query now looks like this:
SELECT TOP (1) 1
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
) OPTION (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL')
, QUERYTRACEON 3604
, QUERYTRACEON 8615
, QUERYTRACEON 8619
, QUERYTRACEON 8620
);
The output is again disappointing. I’ll skip covering it and jump to trace flag 8621. That one adds additional information about the rules and how they interact with memos. With this trace flag we find more information about the plans with merge or loop joins:
Rule Result: group=8 1 LogOp_RightAntiSemiJoin 7 6 5 (Distance = 1) Rule Result: group=8 2 PhyOp_MergeJoin 1-M x_jtRightAntiSemiJoin 7 6 5 (Distance = 2) Rule Result: group=8 3 PhyOp_HashJoinx_jtRightAntiSemiJoin 7 6 5 (Distance = 2) Rule Result: group=8 4 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6 7 5 (Distance = 1) Rule Result: group=8 5 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) Rule Result: group=8 6 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) Rule Result: group=8 7 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5 (Distance = 1) Rule Result: group=8 8 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5 (Distance = 1) Rule Result: group=8 9 PhyOp_MergeJoin 1-M x_jtRightAntiSemiJoin 7 6 5 (Distance = 2) Rule Result: group=8 10 PhyOp_HashJoinx_jtRightAntiSemiJoin 7 6 5 (Distance = 2) Rule Result: group=8 11 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6 7 5 (Distance = 1) Rule Result: group=8 12 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) Rule Result: group=8 13 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) Rule Result: group=8 14 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5 (Distance = 1) Rule Result: group=8 15 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5 (Distance = 1) Rule Result: group=8 16 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5 (Distance = 1) Rule Result: group=8 17 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5 (Distance = 1)
However, group 8 in the final memo still looks the same as before:
Group 8: Card=16935.2 (Max=1.1e+006, Min=0) 11 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.9 7.10 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 26.5569 (Distance = 1) 4 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.4 7.3 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 38.4812 (Distance = 1) 1 LogOp_RightAntiSemiJoin 7 6 5 (Distance = 1) 0 LogOp_LeftAntiSemiJoin 6 7 5 (Distance = 0)
My interpretation is that costing information for the other join types was discarded from the memo. For example, at one point there was an item 5 in group 8 which contained information relevant to costing for one of the nested loop join plans. All of that information is not present in the final plan because the hash join plan was cheaper.
Pray to the Trace Flag Gods
There is an undisclosed trace flag which does not allow items to be discarded from the memo. Obviously this is a dangerous thing to do. However, with that trace flag group 8 finally reveals all of its secrets:
Group 8: Card=16935.2 (Max=1.1e+006, Min=0) 17 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5.0 (Distance = 1) 16 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5.0 (Distance = 1) 15 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5.0 (Distance = 1) 14 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5.0 (Distance = 1) 13 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) 12 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) 11 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.9 7.10 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 26.5569 (Distance = 1) 10 PhyOp_HashJoinx_jtRightAntiSemiJoin 7.8 6 5 (Distance = 2) 9 PhyOp_MergeJoin 1-M x_jtRightAntiSemiJoin 7.6 6 5 (Distance = 2) 8 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 7 5.0 (Distance = 1) 7 PhyOp_LoopsJoinx_jtLeftAntiSemiJoin 6 17 5.0 (Distance = 1) 6 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) 5 PhyOp_Applyx_jtLeftAntiSemiJoin 6 16 (Distance = 1) 4 PhyOp_HashJoinx_jtLeftAntiSemiJoin 6.4 7.3 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 38.4812 (Distance = 1) 3 PhyOp_HashJoinx_jtRightAntiSemiJoin 7.3 6.4 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 48.5597 (Distance = 2) 2 PhyOp_MergeJoin 1-M x_jtRightAntiSemiJoin 7.1 6.2 5.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 106.564 (Distance = 2) 1 LogOp_RightAntiSemiJoin 7 6 5 (Distance = 1) 0 LogOp_LeftAntiSemiJoin 6 7 5 (Distance = 0)
Let’s consider item 5 because it’s one of the more reasonable loop join plan options. Item 5 doesn’t give us direct costing information but it directs us to look to group 16:
Group 16: Card=1 (Max=1, Min=0) 2 PhyOp_Range 1 ASC 5.0 Cost(RowGoal 0,ReW 0,ReB 999999,Dist 1e+006,Total 1e+006)= 165.607 (Distance = 2) 1 PhyOp_Range 1 ASC 5.0 Cost(RowGoal 0,ReW 0,ReB 999999,Dist 1e+006,Total 1e+006 s)= 165.607 (Distance = 2) 0 LogOp_SelectIdx 15 5 (Distance = 1)
We can see a cost of 165.607 for the clustered index seeks on the inner side of the join. If that was the cost used when comparing plans then it explains why the optimizer opted for a hash join over the loop join. We might try looking at a query plan for the following:
DECLARE @TOP INT = 1;
SELECT TOP (@TOP) 1
FROM dbo.OUTER_HEAP o
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.INNER_CI i
WHERE i.ID = o.ID
)
OPTION (OPTIMIZE FOR (@TOP = 987654321)
, LOOP JOIN
, MAXDOP 1);
With the above syntax we will get the same query results as before but the effective TOP (1) cannot change the cost of the query. Here are the operator details for the clustered index seek on INNER_CI:
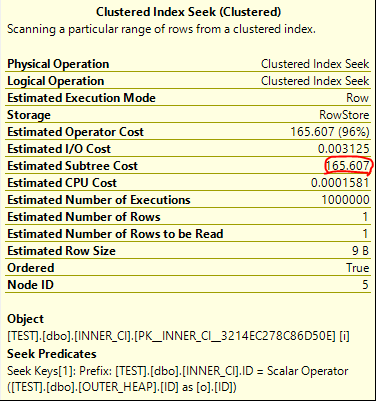
It’s an exact match. The total cost of the query is 172.727 optimizer units, which is significantly more than the price tag of 19.9924 units for the hash join plan.
Improving Displayed Costing
So is there really a problem with the displayed cost of the plan with hints matching (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL'), LOOP JOIN)? After all, the USE HINT seemed to give the correct plan shape without the join hints. Let’s compare the TOP plan side by side with it:

I also uploaded the estimated plans here.
In my view, the costs of the USE HINT plan are nonsensical. The scan and the seeks have matching operator costs of 0.0167621 units. Bizarrely, this also matches the final query cost. 0.0167621 + 0.0167621 = 0.0167621. It’s totally unclear where these numbers come from, and if a TOP (1) can aggressively discount all of the operators in a plan then it seems like the DISABLE_OPTIMIZER_ROWGOAL hint will not have its intended practical impact. Certainly a TOP (1) will not discount the costs of blocking operators, so plans without them (such as loop joins) will be costed cheaper than plans with them (like hash joins).
I would prefer to see matching query costs for both subtrees. Of course, the TOP (1) can influence the costs of other parts of the plan that depend on this subtree, so the estimate needs to obey the TOP expression. I just feel that it shouldn’t affect the cost of the immediate subtree.
If you’re curious where the 0.016762 number comes from, I suspect that it has something to do with the TOP (1) capping the cost of the nested loop join. The following can be found in the final memo:
Group 11: Card=1 (Max=1, Min=0) 1 PhyOp_Top 8.2 9.0 10.0 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 0.016762 (Distance = 1) Group 8: Card=16935.2 (Max=1.1e+006, Min=0) 2 PhyOp_Applyx_jtLeftAntiSemiJoin 6.4 15.2 Cost(RowGoal 0,ReW 0,ReB 0,Dist 0,Total 0)= 172.723 (Distance = 1)
In addition, the query cost slightly increases when I change the query to return the first 2 rows. You could argue that query plan costs are just numbers and there’s no reason to care about them as long as you get the right plan, but that’s not quite true. I’m sure this isn’t an exhaustive list, but query plan costs can affect at least the following:
- If the query cost is too low it won’t be eligible for a parallel plan.
- The number of seconds that a query will wait for a memory grant before throwing an error.
- The amount of steps taken by the optimizer during query plan creation.
- If the query is sent to a small query resource semaphore.
- If the query is not able to run due to the query governor cost limit.
Final Thoughts
Congrats if you made it to the end. Thanks for reading!