This is part 1 of a series on columnstore index partitioning. The focus of this post is on rowgroup elimination.
Defining Fragmentation for CCIs
There are many different ways that a CCI can be fragmented. Microsoft considers having multiple delta rowgroups, deleted rows in compressed rowgroups, and compressed rowgroups less than the maximum size all as signs of fragmentation. I’m going to propose yet another way. A CCI can also be considered fragmented if the segments for a column that is very important for rowgroup elimination are packed in such a way that limits rowgroup elimination. That sentence was a bit much but the following table examples should illustrate the point.
The Test Data
First we’ll create a single column CCI with integers from 1 to 104857600. I’ve written the query so that the integers will be loaded in order. This is more commonly done using a loop and I’m relying slightly on undocumented behavior, but it worked fine in a few tests that I did:
DROP TABLE IF EXISTS dbo.LUCKY_CCI; CREATE TABLE dbo.LUCKY_CCI ( ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.LUCKY_CCI WITH (TABLOCK) SELECT TOP (100 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ORDER BY RN OPTION (MAXDOP 1);
On my machine, the table takes less than 40 seconds to populate. We can see that the minimum and maximum IDs for each rowgroup are nice and neat from the sys.column_store_segments DMV:
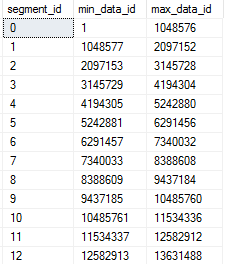
This table does not have any rowgroup elimination fragmentation. The segments are optimally constructed from a rowgroup elimination point of view. SQL Server will be able to skip every rowgroup except for one or two if I filter on a sequential range of one million integers:
SELECT COUNT(*) FROM dbo.LUCKY_CCI WHERE ID BETWEEN 12345678 AND 13345677;
STATISTICS IO output:
Table ‘LUCKY_CCI’. Segment reads 2, segment skipped 98.
Erik Darling was the inspiration for this next table, since he can never manage to get rowgroup elimination in his queries. The code below is designed to create segments that allow for pretty much no rowgroup elimination whatsoever:
DROP TABLE IF EXISTS dbo.UNLUCKY_CCI; CREATE TABLE dbo.UNLUCKY_CCI ( ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ); INSERT INTO dbo.UNLUCKY_CCI WITH (TABLOCK) SELECT rg.RN FROM ( SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 ) driver CROSS APPLY ( SELECT driver.RN UNION ALL SELECT 104857601 - driver.RN UNION ALL SELECT TOP (1048574) 100 + 1048574 * (driver.RN - 1) + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t2 CROSS JOIN master..spt_values t3 ) rg ORDER BY driver.RN OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL);
Each rowgroup will contain an ID near the minimum (1 – 100) and an ID near the maximum (104857301 – 104857400). We can see this with the same DMV as before:
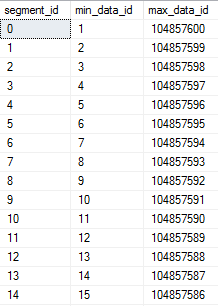
This table has pretty much the worst possible rowgroup elimination fragmentation. SQL Server will not be able to skip any rowgroups when querying almost any sequential range of integers:
SELECT COUNT(*) FROM dbo.UNLUCKY_CCI WHERE ID BETWEEN 12345678 AND 13345677;
STATISTICS IO output:
Table ‘UNLUCKY_CCI’. Segment reads 100, segment skipped 0.
Measuring Rowgroup Elimination Fragmentation
It might be useful to develop a more granular measurement for rowgroup elimination instead of just “best” and “worst”. One way to approach this problem is to define a batch size in rows for a filter against the column and to estimate how many total table scans would need to be done if the entire table was read in a series of SELECT queries with each processing a batch of rows. For example, with a batch size of 1048576 query, 1 would include the IDs from 1 to 1048576, query 2 would include IDs from 1 + 1048576 to 1048576 * 2, and so on. I will call this number the rowgroup elimination fragmentation factor, or REFF for short. It roughly represents how many extra rowgroups are read that could have been skipped with less fragmentation. Somewhat-tested code to calculate the REFF is below:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; DECLARE @batch_size INT = 1048576; DECLARE @global_min_id BIGINT; DECLARE @global_max_id BIGINT; DECLARE @segments BIGINT; DROP TABLE IF EXISTS #MIN_AND_MAX_IDS; CREATE TABLE #MIN_AND_MAX_IDS ( min_data_id BIGINT, max_data_id BIGINT ); CREATE CLUSTERED INDEX c ON #MIN_AND_MAX_IDS (min_data_id, max_data_id); INSERT INTO #MIN_AND_MAX_IDS SELECT css.min_data_id, css.max_data_id FROM sys.objects o INNER JOIN sys.columns c ON o.object_id = c.object_id INNER JOIN sys.partitions p ON o.object_id = p.object_id INNER JOIN sys.column_store_segments css ON p.hobt_id = css.hobt_id AND css.column_id = c.column_id INNER JOIN sys.dm_db_column_store_row_group_physical_stats s ON o.object_id = s.object_id AND css.segment_id = s.row_group_id AND s.partition_number = p.partition_number WHERE o.name = 'LUCKY_CCI' AND c.name = 'ID' AND s.[state] = 3; SET @segments = @@ROWCOUNT; SELECT @global_min_id = MIN(min_data_id) , @global_max_id = MAX(max_data_id) FROM #MIN_AND_MAX_IDS; DROP TABLE IF EXISTS #BUCKET_RANGES; CREATE TABLE #BUCKET_RANGES ( min_data_id BIGINT, max_data_id BIGINT ); -- allows up to 6.4 million pieces INSERT INTO #BUCKET_RANGES SELECT @global_min_id + (RN - 1) * @batch_size , @global_min_id + RN * @batch_size - 1 FROM ( SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t WHERE -- number of buckets t.RN <= CEILING((1.0 * @global_max_id - (@global_min_id)) / @batch_size); -- number of total full scans SELECT 1.0 * SUM(cnt) / @segments FROM ( SELECT COUNT(*) cnt FROM #BUCKET_RANGES br LEFT OUTER JOIN #MIN_AND_MAX_IDS m ON m.min_data_id <= br.max_data_id AND m.max_data_id >= br.min_data_id GROUP BY br.min_data_id ) t;
For the LUCKY_CCI table, if we pick a batch size of 1048576 we get a REFF of 1.0. This is because each SELECT query would read exactly 1 rowgroup and skip the other 99 rowgroups. Conversely, the UNLUCKY_CCI table has a REFF of 100.0. This is because every SELECT query would need to read all 100 rowgroups just to return 1048576 rows. In other words, each query does a full scan of the table and there are 100 rowgroups in the table.
What about DUIs?
Suppose our lucky table runs out of luck and starts getting DUIs. As rows are deleted and reinserted they will be packed into new rowgroups. We aren’t likely to keep our perfect rowgroups for every long. Below is code that randomly deletes and inserts a range of 100k integers. There is some bias in which numbers are processed but that’s ok for this type of testing. I ran the code with 600 loops which means that up to 60% of the rows in the table could have been moved around. There’s nothing special about 60%. That just represents my patience with the process.
DECLARE @target_loops INT = 600, @batch_size INT = 100001, @current_loop INT = 1, @middle_num BIGINT, @rows_in_target BIGINT; BEGIN SET NOCOUNT ON; SELECT @rows_in_target = COUNT(*) FROM dbo.LUCKY_CCI; DROP TABLE IF EXISTS #num; CREATE TABLE #num (ID INT NOT NULL); INSERT INTO #num WITH (TABLOCK) SELECT TOP (@batch_size) -1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2; WHILE @current_loop <= @target_loops BEGIN SET @middle_num = CEILING(@rows_in_target * RAND()); DELETE tgt WITH (TABLOCK) FROM dbo.LUCKY_CCI tgt WHERE tgt.ID BETWEEN CAST(@middle_num - FLOOR(0.5*@batch_size) AS BIGINT) AND CAST(@middle_num + FLOOR(0.5*@batch_size) AS BIGINT); INSERT INTO dbo.LUCKY_CCI WITH (TABLOCK) SELECT @middle_num + n.ID - FLOOR(0.5 * @batch_size) FROM #num n WHERE n.ID BETWEEN 1 AND @rows_in_target OPTION (MAXDOP 1); SET @current_loop = @current_loop + 1; END; END;
Our table now has a bunch of uncompressed rowgroups and many compressed rowgroups with lots of deleted rows. Let’s clean it up with a REORG:
ALTER INDEX CCI ON dbo.LUCKY_CCI REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
This table has a REFF of about 41 for a batch size of 1048576. That means that we can expect to see significantly worse rowgroup elimination than before. Running the same SELECT query as before:
Table ‘LUCKY_CCI’. Segment reads 51, segment skipped 75.
The LUCKY_CCI table clearly needs to be renamed.
The Magic of Partitioning
A partition for a CCI is a way of organizing rowgroups. Let’s create the same table but with partitions that can hold five million integers. Below is code to do that for those following along at home:
CREATE PARTITION FUNCTION functioning_part_function (BIGINT) AS RANGE RIGHT FOR VALUES ( 0 , 5000000 , 10000000 , 15000000 , 20000000 , 25000000 , 30000000 , 35000000 , 40000000 , 45000000 , 50000000 , 55000000 , 60000000 , 65000000 , 70000000 , 75000000 , 80000000 , 85000000 , 90000000 , 95000000 , 100000000 , 105000000 ); CREATE PARTITION SCHEME scheming_part_scheme AS PARTITION functioning_part_function ALL TO ( [PRIMARY] ); DROP TABLE IF EXISTS dbo.PART_CCI; CREATE TABLE dbo.PART_CCI ( ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE ) ON scheming_part_scheme(ID); INSERT INTO dbo.PART_CCI WITH (TABLOCK) SELECT TOP (100 * 1048576) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 CROSS JOIN master..spt_values t3 ORDER BY RN OPTION (MAXDOP 1);
5 million was a somewhat arbitrary choice. The important thing is that it’s above 1048576 rows. Generally speaking, picking a partition size below 1048576 rows is a bad idea because the table’s rowgroups will never be able to reach the maximum size.
Using the sys.dm_db_column_store_row_group_physical_stats dmv we can see that rowgroups were divided among partitions as expected:
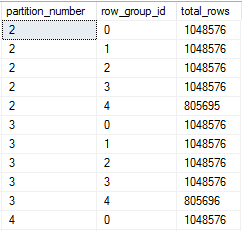
This table has a REFF of 1.9 for a batch size of 1048576. This is perfectly reasonable because the partition size was defined as 5 * 1000000 instead of 5 * 1048576 which would be needed for a REFF of 1.0.
Now I’ll run the same code as before to do 60 million DUIs against the table. I expect the partitions to limit the damage because row cannot move out of their partitions. After the process finishes and we do a REORG, the table has a REFF of about 3.7. The rowgroups are definitely a bit messier:

Running our SELECT query one last time:
SELECT COUNT(*) FROM dbo.Part_CCI WHERE ID BETWEEN 12345678 AND 13345677;
We see the following numbers for rowgroup elimination:
Table ‘PART_CCI’. Segment reads 4, segment skipped 3.
Only four segments are read. Many segments are skipped, including all of those in partitions not relevant to the query.
Final Thoughts
Large, unpartitioned CCIs will eventually run into issues with rowgroup elimination fragmentation if the loading process can delete data. A maintainance operation that rebuilds the table with a clustered rowstore index and rebuilds the CCI with MAXDOP = 1 is one way to restore nicely organized rowgroups, but that is a never-ending battle which grows more expensive as the table gets larger. Picking the right partitioning function can guarantee rowgroup elimination fragmentation. Thanks for reading!

One thought on “CCI Partitioning Part 1: Rowgroup Elimination Fragmentation”