Adaptive joins are a new feature in SQL Server 2017. For adaptive join operators the decision to do a hash or loop join is deferred until enough input rows are counted. You can get an introduction on the topic in this blog post by Joe Sack. Dmitry Pilugin has an excellent post digging into the internals. The rest of this blog post assumes that you know the basics of adaptive joins.
Getting an Adaptive Join
It’s pretty easy to create a query that has an adaptive join in SQL Server 2017. Below I create a CCI with 100k rows and an indexed rowstore table with 400k rows:
DROP TABLE IF EXISTS dbo.MY_FIRST_CCI;
CREATE TABLE dbo.MY_FIRST_CCI (
FILTER_ID_1 INT NOT NULL,
FILTER_ID_2 INT NOT NULL,
FILTER_ID_3 INT NOT NULL,
JOIN_ID INT NOT NULL,
INDEX CI CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.MY_FIRST_CCI WITH (TABLOCK)
SELECT TOP (100000)
t.RN
, t.RN
, t.RN
, t.RN
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
OPTION (MAXDOP 1);
ALTER TABLE dbo.MY_FIRST_CCI REBUILD WITH (MAXDOP = 1);
CREATE STATISTICS S1 ON dbo.MY_FIRST_CCI (FILTER_ID_1)
WITH FULLSCAN;
CREATE STATISTICS S2 ON dbo.MY_FIRST_CCI (FILTER_ID_2)
WITH FULLSCAN;
CREATE STATISTICS S3 ON dbo.MY_FIRST_CCI (FILTER_ID_3)
WITH FULLSCAN;
CREATE STATISTICS S4 ON dbo.MY_FIRST_CCI (JOIN_ID)
WITH FULLSCAN;
DROP TABLE If exists dbo.SEEK_ME;
CREATE TABLE dbo.SEEK_ME (
JOIN_ID INT NOT NULL,
PADDING VARCHAR(2000) NOT NULL,
PRIMARY KEY (JOIN_ID)
);
INSERT INTO dbo.SEEK_ME WITH (TABLOCK)
SELECT TOP (400000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
, REPLICATE('Z', 2000)
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CREATE STATISTICS S1 ON dbo.SEEK_ME (JOIN_ID)
WITH FULLSCAN;
The full scan stats are just there to show that there isn’t any funny business with the stats. The below query gets an adaptive join:
SELECT * FROM dbo.MY_FIRST_CCI o INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID
It’s obvious when it happens in SSMS:

It’s possible to get an adaptive join with even simpler table definitions. I created the tables this way because they’ll be used for the rest of this post.
Adaptive Threshold Rows
Unlike some other vendors, Microsoft was nice enough to expose the adaptive row threshold in SSMS when looking at estimated or actual plans:
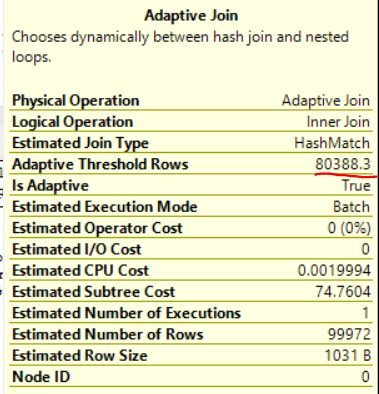
The adaptive join saves input rows to a temporary structure and acts as a blocking operator until it makes a decision about which type of join to use. In this example, if there are less than 80388.3 rows then the adaptive join will execute as a nested loop join. Otherwise it’ll execute as a hash join.
The adaptive threshold row count can change quite a bit based on the input cardinality estimate. It changes to 22680 rows if I add the following filter that results in a single row cardinality estimate:
WHERE o.FILTER_ID_1 = 1
It was surprising to me to see so much variance for this query. There must be some overhead with doing the adaptive join but I wouldn’t expect the tipping point between a loop and hash join to change so dramatically. I would expect it to be close to a traditional tipping point calculated without adaptive joins.
Traditional Tipping Point
Let’s disable adaptive joins using the 'DISABLE_BATCH_MODE_ADAPTIVE_JOINS' USE HINT and consider how an execution plan would look for this query:
SELECT *
FROM dbo.MY_FIRST_CCI o
INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID
WHERE o.FILTER_ID_1 BETWEEN @start AND @end
OPTION (
RECOMPILE,
USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
);
We should expect a hash join if the local variables don’t filter out as many rows. Conversely, we should expect a loop join if the local variables on FILTER_ID_1 filter out many rows from the table. There’s a tipping point where the plan will change from a hash join to a loop join if we filter out a single additional row . On my machine, the tipping point is between 48295 and 48296 rows:

The estimated costs for the two queries are very close to each other: 74.6842 and 74.6839 optimizer units. However, we saw earlier that the tipping point for an adaptive join on this query can vary between 22680 and 80388.3 rows. This inconsistency means that we can find a query that performs worse with adaptive joins enabled.
The Regression
After some trial and error I found the following query:
SELECT * FROM dbo.MY_FIRST_CCI o INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID WHERE o.FILTER_ID_1 BETWEEN 1 AND 28000 AND o.FILTER_ID_2 BETWEEN 1 AND 28000 AND o.FILTER_ID_3 BETWEEN 1 AND 28000 ORDER BY (SELECT NULL) OFFSET 100001 ROWS FETCH NEXT 1 ROW ONLY OPTION (MAXDOP 1);
The ORDER BY stuff isn’t important. It’s there just to not send any rows over the network. Here’s the plan:

The query has a cardinality estimate of 10777.7 rows coming out of the MY_FIRST_CCI table. The adaptive join has a tipping point of 27611.6 rows. However, I’ve constructed the table and the filter such that 28000 rows will be sent to the join. SQL Server expects a loop join, but it will instead do a hash join because 28000 > 27611.6. With a warm cache the query takes almost half a second:
CPU time = 469 ms, elapsed time = 481 ms.
If I disable adaptive joins, the query finishes in less than a fifth of a second:
CPU time = 172 ms, elapsed time = 192 ms.
A loop join is a better choice here, but the adaptive row threshold makes the adaptive join pick a hash join.
Final Thoughts
This post contains only a single test query, so it’s no cause for panic. It’s curious that Microsoft made the adaptive join tipping so dependent on cardinality estimates going into the join. I’m unable to figure out the design motivation for doing that. I would expect the other side of the join to be much more important. Thanks for reading!

2 thoughts on “An Adaptive Join Regression”